










Koneoppiminen (ML) ja tekoäly (AI – joista ML voidaan nähdä tekoälyn osajoukkona) on perinteisesti toteutettu korkean suorituskyvyn laskentajärjestelmissä ja viime vuosina yhä enemmän pilvessä. Nyt niitä kuitenkin hyödynnetään yhä useammin sovelluksissa, joissa käsittely tapahtuu lähellä datan lähdettä. Tämä on ihanteellista IoT-laitteille: kun analyysi tehdään reunalla, pilveen tarvitsee lähettää vähemmän dataa. Tulos on parempi suorituskyky pienemmän viiveen ansiosta ja parempi tietoturva.
|
Artikkelin kirjoittaja Yann LeFaou toimii Microchipin Touch and Gesture (TXFG) -liiketoimintayksikön apulaisjohtajana. |
ML/AI vie reunalaskennan seuraavalle tasolle mahdollistamalla päätelmien teon suoraan datalähteessä. IoT-laite voi tämän ansiosta oppia ja kehittyä kokemuksen perusteella. Algoritmit analysoivat dataa etsiäkseen malleja ja tehdäkseen päätelmiä kolmen oppimistyypin avulla: valvottu, valvomaton ja vahvistettu oppiminen.
Valvottu oppiminen perustuu merkittyyn opetusdataan. Esimerkiksi älykamera voidaan kouluttaa valokuvilla ja videoilla, joissa ihmiset seisovat, kävelevät, juoksevat tai kantavat laatikoita. Tällaisissa algoritmeissa, kuten logistisessa regressiossa ja Naive Bayes -menetelmässä, mallia kehitetään jatkuvasti palautteen avulla.
Valvomaton oppiminen käyttää merkitsemätöntä dataa ja algoritmeja, kuten K Means -klusterointia ja pääkomponenttianalyysiä, tunnistaakseen piileviä malleja. Tämä sopii erinomaisesti poikkeamien havaitsemiseen. Esimerkiksi ennakoivan kunnossapidon tai lääketieteellisen kuvantamisen yhteydessä kone voi havaita poikkeavia ilmiöitä verrattuna siihen, mitä se on oppinut pitämään “tavanomaisena”.
Vahvistettu oppiminen perustuu “kokeilun ja erehdyksen” menetelmään. Kuten valvotussa oppimisessa, palautetta tarvitaan, mutta sitä käsitellään palkkiona tai rangaistuksena. Tyypillisiä algoritmeja ovat Monte Carlo ja Q-learning.
Näissä esimerkeissä yhteisenä tekijänä on sulautettu konenäkö, joka muuttuu “älykkääksi” ML/AI:n avulla. Tällaisesta näköpohjaisesta päätelmästä voivat hyötyä monet muutkin sovellukset. Älykäs konenäkö voi hyödyntää myös aallonpituuksia, joita ihmissilmä ei näe, kuten infrapunaa (lämpökuvantaminen) tai ultraviolettivaloa.
Kun ML/AI-reunajärjestelmää täydennetään muilla datalähteillä – kuten lämpötila- ja tärinämittauksilla – teolliset IoT-laitteet voivat olla keskeinen osa yrityksen ennakoivan kunnossapidon strategiaa. Ne voivat myös antaa varhaisia varoituksia odottamattomista vioista ja siten suojata laitteistoa, tuotteita ja henkilöstöä.
Sulautetut järjestelmät
Kuten artikkelin alussa todettiin, ML/AI vaati aiemmin huomattavia laskentaresursseja. Nykyään – sovelluksen monimutkaisuudesta riippuen – ML ja AI voidaan toteuttaa komponenteilla, joita käytetään tyypillisesti sulautetuissa järjestelmissä, kuten IoT-laitteissa.
Esimerkiksi kuvantunnistus ja -luokittelu voidaan toteuttaa FPGA-piireillä tai mikroprosessoreilla (MPU). Lisäksi yksinkertaisempia sovelluksia, kuten tärinän valvontaa ja analysointia (ennakoivaa kunnossapitoa varten), voidaan toteuttaa jopa 8-bittisillä mikrokontrollereilla (MCU).
Aiemmin ML/AI:n kehittäminen vaati huippuasiantuntijoita suunnittelemaan kuvioiden tunnistamiseen sopivia algoritmeja ja päivitettäviä malleja. Näin ei kuitenkaan enää ole. Sulautettujen järjestelmien insinööreillä, jotka tuntevat reunalaskennan, on nyt käytössään tarvittavat laitteistot, ohjelmistot, työkalut ja menetelmät ML/AI:ta hyödyntävien tuotteiden suunnitteluun. Lisäksi monet mallit ja opetusdatat ovat vapaasti saatavilla, ja useat piirivalmistajat tarjoavat integroituja kehitysympäristöjä (IDE) ja kehityspaketteja, jotka nopeuttavat ML/AI-sovellusten kehitystä.
Esimerkiksi Microchipin MPLAB X IDE sisältää työkaluja, joilla insinöörit voivat löytää, konfiguroida, kehittää, testata ja validoida sulautettuja suunnitelmia. Koneoppimisen kehityspaketti (plug-in) mahdollistaa ML-mallien suoran ohjelmoinnin kohdelaitteeseen. Tämä paketti hyödyntää AutoML-menetelmää, joka automatisoi monia aikaa vieviä ja toistuvia vaiheita, kuten mallien kehityksen ja koulutuksen (ks. kuva 1).
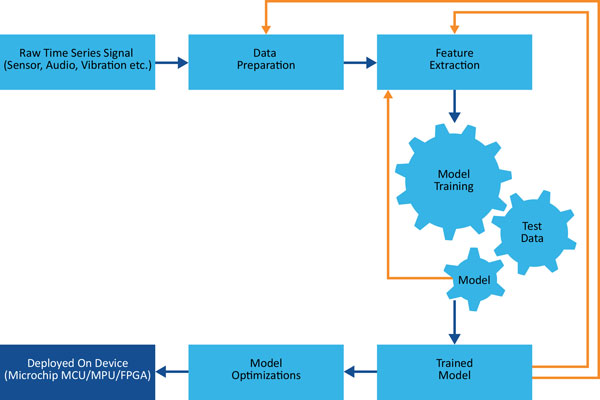
Kuva 1. ML/AI-mallien kehitys on iteratiivinen prosessi.
Vaikka nämä vaiheet voidaan automatisoida, suunnittelun optimointi on silti oma haasteensa. Jopa kokeneet reunalaskentaa suunnitelleet insinöörit voivat kohdata vaikeuksia ML/AI-projekteissa. On tehtävä kompromisseja suorituskyvyn (johon vaikuttavat mallin koko ja datan määrä), virrankulutuksen ja kustannusten välillä. Kuvassa 2 esitetään Microchipin laitetyyppejä, joita käytetään tyypillisesti ML-päätelmissä, sekä niiden suorituskyvyn, kustannusten ja tehonkulutuksen välinen suhde.

Kuva 2.Esimerkkejä laite- ja sovellustyypeistä ML-päätelmissä.
Pienikokoisten järjestelmien suunnittelu
Kuten mainittua, jopa 8-bittisiä MCU-piirejä voidaan käyttää joissakin ML-sovelluksissa. Yksi merkittävä tekijä tämän mahdollistamisessa on tinyML, joka tuo ML/AI:n resurssirajoitteisille mikrokontrollereille.
Tarkastellaanpa tätä lukujen valossa. Tyypillinen ML/AI:ta varten suunniteltu huipputason MCU tai MPU toimii 1–4 GHz:n taajuudella, tarvitsee 512 Mt – 64 Gt RAM-muistia ja 64 Gt – 4 Tt tallennustilaa. Virrankulutus on 30–100 W.
tinyML puolestaan on suunniteltu MCU:ille, jotka toimivat 1–400 MHz:n taajuudella, käyttävät 2–512 kt RAM-muistia ja 32 kt – 2 Mt pysyvää muistia. Virrankulutus on vain 150 µW – 23,5 mW, mikä sopii täydellisesti akku- tai energianlouhintakäyttöisiin sovelluksiin.
tinyML:n onnistunut toteutus perustuu datan keräämiseen ja valmisteluun sekä mallin kehittämiseen ja optimointiin. Näistä datan valmistelu on ratkaisevaa, jotta oppimisprosessin eri vaiheissa on käytettävissä laadukas tietoaineisto (ks. kuva 3).

Kuva 3. Koneoppimisen prosessi.
Opetusvaiheessa tarvitaan datasetti valvotuille (ja puolivalvotuille) malleille. Datasetti on jäsennelty tietokokonaisuus, jossa data on usein myös nimetty. Kuten älykkään kameran esimerkissä, opetusdata voi sisältää kuvia ihmisistä eri asennoissa ja liikkeissä. Datan voi tuottaa itse tai käyttää valmiita aineistoja, kuten MPII Human Pose, joka sisältää noin 25 000 kuvaa verkosta kerätyistä videoista.
Datasetti täytyy kuitenkin optimoida käyttöön. Liian suuri määrä dataa täyttää nopeasti muistin, kun taas liian pieni aineisto johtaa virheellisiin tai epäluotettaviin tuloksiin.
Myös ML/AI-mallin täytyy olla kompakti. Yksi yleinen pakkausmenetelmä on weight pruning, jossa joidenkin neuronien välisiä yhteyksiä poistetaan (asetetaan painoarvo nollaksi), jolloin ne eivät osallistu päätelmiin. Toisessa menetelmässä, kvantisoinnissa, mallin parametrit muunnetaan tarkemmasta muodosta (esim. 32-bittinen liukuluku, FP32) vähemmän tarkkaan muotoon (esim. 8-bittinen kokonaisluku, INT8).
Kun datasetti on optimoitu ja malli tiivistetty, voidaan valita sopiva MCU. Tätä varten on olemassa kehityskehyksiä, kuten TensorFlow Lite, joka mahdollistaa uusien mallien rakentamisen tai olemassa olevien uudelleenkouluttamisen. Malli voidaan sen jälkeen pakata ja kvantisoida ennen sen lataamista kohdelaitteeseen.
Yhteenveto
ML ja AI käyttävät algoritmisia menetelmiä mallien ja trendien tunnistamiseen sekä ennusteiden tekemiseen. Kun ML/AI sijoitetaan lähelle datalähdettä – eli reunalle – sovellukset voivat tehdä päätelmiä ja toimia reaaliaikaisesti, mikä tekee koko järjestelmästä tehokkaamman ja turvallisemman.
Saatavilla olevien laitteistojen, kehitysympäristöjen, työkalujen, kehityspakettien, kehysten, datasetien ja avoimen lähdekoodin mallien ansiosta insinöörit voivat nykyään kehittää ML/AI-pohjaisia reunalaskentasovelluksia suhteellisen helposti.
Nämä ovat innostavia aikoja sulautettujen järjestelmien insinööreille ja koko teollisuudelle. On kuitenkin tärkeää välttää ylisuunnittelu: liian tehokkaiden ja kalliiden piirien käyttö voi nostaa kustannuksia ja virrankulutusta tarpeettomasti.
|
Artikkeli on ilmestynyt uusimmassa ETNdigi-lehdessä. Sen pääset lukemaan täällä. |





 Kun suurteholaskennan (HPC) työkuormat monimutkaistuvat, generatiivinen tekoäly sulautuu yhä tiiviimmin moderneihin järjestelmiin ja lisää kehittyneiden muistiratkaisujen tarvetta. Vastatakseen näihin muuttuviin vaatimuksiin ala kehittää uuden sukupolven muistiarkkitehtuureja, jotka maksimoivat kaistanleveyden, minimoivat latenssin ja parantavat energiatehokkuutta.
Kun suurteholaskennan (HPC) työkuormat monimutkaistuvat, generatiivinen tekoäly sulautuu yhä tiiviimmin moderneihin järjestelmiin ja lisää kehittyneiden muistiratkaisujen tarvetta. Vastatakseen näihin muuttuviin vaatimuksiin ala kehittää uuden sukupolven muistiarkkitehtuureja, jotka maksimoivat kaistanleveyden, minimoivat latenssin ja parantavat energiatehokkuutta.