









 Datamäärän räjähdys on johtanut tekoälyn ja koneoppimisen (ML) sovellusten valtavaan kasvuun, joissa muisti ja tallennustila ovat avainasemassa sovellusten onnistumisessa ja nopeudessa. Perinteisiä muisti- ja tallennusjärjestelmiä ei ole suunniteltu näiden suurien tietojoukkojen käsittelyyn, joten tietotekniikan tekoäly- ja ML-sovellusten keskeinen haaste on lyhentää etsintään ja käsittelyyn kuluvaa aikaa.
Datamäärän räjähdys on johtanut tekoälyn ja koneoppimisen (ML) sovellusten valtavaan kasvuun, joissa muisti ja tallennustila ovat avainasemassa sovellusten onnistumisessa ja nopeudessa. Perinteisiä muisti- ja tallennusjärjestelmiä ei ole suunniteltu näiden suurien tietojoukkojen käsittelyyn, joten tietotekniikan tekoäly- ja ML-sovellusten keskeinen haaste on lyhentää etsintään ja käsittelyyn kuluvaa aikaa.
|
Artikkelin kirjoittaja Arthur Sainio on SMART Modular Technologiesin tuotemarkkinoinnin johtaja. Hän vastaa uusien teknologioiden kuten MRAM- ja NVDIMM-muistien kehittämisestä IIoT-, tietoliikenne-, ilmailu- ja puolustussovelluksiin. Ennen SMART Modular Technologiesin palvelukseen siirtymistään hän toimi markkinointijohtajana Hitachi Semiconductorilla. Arthurilla on tutkinnot San Francisco State- ja Arizona State -yliopistoista. |
Ennen kuin mennään yksityiskohtiin siinä, miksi muisti ja tallennustila ovat välttämättömiä tekoäly- ja ML-sovelluksille, on tärkeää ymmärtää, miten ne toimivat. Muistia tai tarkemmin sanottuna DRAM-muistia tarvitaan paikaksi, johon tallennetaan data, joka pitää mahdollisimman nopeasti muuntaa hyödylliseksi informaatioksi. Tallennustilaa tai tarkemmin flashia tarvitaan sekä raakadatan että muunnettujen tietojen tallentamiseen, jotta ne eivät häviä. Datan muistin ja tallennuksen perusprosessi on "syöttäminen, muuntaminen ja päättäminen" niin nopeasti kuin mahdollista.
Palvelimet ja tekoäly
Tekoälyn kehittämiseen käytettävät palvelimet ovat siirtyneet keskusprosessoreihin keskittyvistä kokoonpanoista useita GPU- eli grafiikkaprosessoreja käyttäviin kokoonpanoihin. Tekoälypalvelimilla on huomattavasti enemmän laskenta- ja muistikapasiteettia verrattuna perinteisiin palvelimiin, joita tarvitaan moninkertaisiin ja nopeisiin työkuormiin. Tekoälyn kehitys vaikuttaa laitearkkitehtuureihin, kun kehittäjät siirtyvät perinteisistä arkkitehtuureista sellaisiin, jotka hyödyntävät uutta tekniikkaa työnkulun nopeuttamiseksi.

Tutkimuslaitos Gartnerin mukaan sekä päättely- että koulutuspalvelimet tarjoavat entistä parempia käsittelynopeuksia muisti- ja tallennustoiminnoille tekoäly- ja ML-sovelluksiin.
Päättelypalvelimet käyttävät Gartnerin mukaan ennusteen tekoon koulutettua koneoppimisalgoritmia. IoT-dataa voidaan käyttää syötteenä koulutettuun koneoppimismalliin, mikä antaa mahdollisuuden ennusteisiin, jotka voivat ohjata päätöksentekologiikkaa laitteessa, reunayhdyskäytävässä tai muualla IoT-järjestelmässä. Nämä palvelimet tarjoavat merkittävästi paremman prosessoinnin suorituskyvyn ja vaativat lähes 20 prosenttia enemmän DRAM-muistia kuin tavalliset palvelimet.
Koulutuspalvelimet - esimerkiksi Nvidia-pohjaiset GPU-palvelimet, jotka on yhdistetty suuriksi tekoälyohjelmistojen koulutusverkoiksi - mahdollistavat Facebook-sovellusten tunnistaa esineitä ja kasvoja, kääntää tekstiä reaaliajassa ja kuvailla ja tulkita valokuvia ja videoita. Tässä syväoppimisen (deep learning) aikana opitut kyvyt otetaan käyttöön. Koulutuspalvelimet käyttävät esimerkkinä Nvidian kiihdytinkortteja ja tuovat käyttöön noin 2,5 kertaa enemmän DRAM-muistia kuin tavalliset palvelimet.
Tekoälyn DRAM-muisti
Suurempaa muistin kaistanleveyttä ja alhaisempaa viivettä tarvitaan tehokkaampaan rinnakkaislaskentaan. GPU-prosessorit tarjoavat vaaditun kaistanleveyden, prosessointinopeuden ja vastaavat AI- ja ML-sovellusten edellyttämään työnkuorman kasvuun. Tavoitteena on päästä raakadatasta analytiikkaan ja edelleen toimintaan lyhyimmällä mahdollisella viiveellä. ML-koulutuspalvelimissa käytettävät grafiikkasuorittimet on yhdistettävä oikeantyyppiseen ja oikeaan määrään muistia suorituskyvyn optimoimiseksi. Eri grafiikkaprosessoreilla on erilaiset muistivaatimukset. Esimerkiksi Nvidian DGX-1-tekoälyjärjestelmässä on 8 grafiikkasuoritinta, joista jokaisessa on 16 gigatavua sisäistä muistia. Järjestelmän päämuistin kapasiteettivaatimus on 512 gigatavua, joka koostuu 16 x 32 gigatavun DDR4 LRDIMM -muisteista. LRDIMM-moduulit on suunniteltu maksimoimaan AI-palvelimien kapasiteetti ja kaistanleveys, varsinkin kun CPU-prosessorit eivät tarjoa tarpeeksi muistikanavia yli 8 RDIMM-muistimoduulin sijoittamiseen. Tämä on DGX-1:n sisältä löytyvien Broadwell-suorittimien rajoitus.
Eri muistityypit ja erilaiset DIMM-kokoonpanot palvelimissa edellyttävät kompromisseja suorituskyvyn ja kapasiteetin välillä. LRDIMM-moduulit on suunniteltu minimoimaan kuormitus ja maksimoimaan kapasiteetti. LRDIMM:t käyttävät puskuripiiriä skaalautuvaan suorituskykyyn. RDIMM-moduulit ovat tyypillisesti nopeampia ja parantavat signaalin eheyttä pitämällä rekisteriä DIMM-moduulissa puskuroimaan osoite- ja komentosignaalit jokaisen DIMM-moduulin DRAM-muistin ja muistiohjaimen välillä. Tämän ansiosta jokaisessa muistikanavassa voidaan käyttää jopa kolmea ns. dual-rank-tyyppistä DIMM-moduulia.
LRDIMM-moduulit käyttävät muistipuskureita tasoittamaan LRDIMM-moduulin rivien sähkökuormat yhteen sähkökuormaan, jolloin niillä voi olla jopa kahdeksan riviä yhdessä DIMM-moduulissa. RDIMM-moduuleja käytettäessä järjestelmän suorituskyky heikkenee, kun kaikki muistipaikat ovat täynnä. Näin käy Broadwell-suorittimissa ja vanhemmissa Intel-suorittimissa. Intelin Skylake- ja Cascade Lake -sarjan suorittimien kohdalla muistikanavan rajoituksia ei enää ole. Sama koskee AMD:n Rome- ja Milan-polvien prosessoreita. Tämän takia RDIMM-moduulit ovat markkinoiden nopein ja halvin ratkaisu.
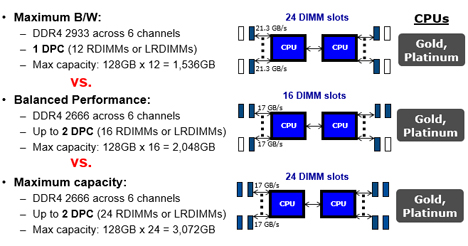
Kuva 1. Kaistanleveyden ja suorituskyvyn vertailu Intelin Cascade Lake -sarjan prosessoreita käytettäessä.
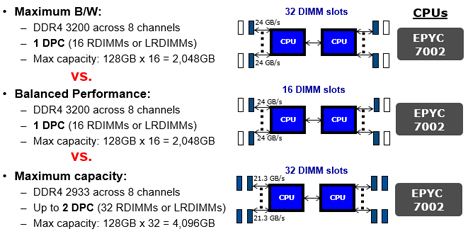
Kuva 2. Kaistanleveyden ja suorituskyvyn vertailu AMD:n Rome-sarjan prosessoreita käytettäessä.
Flashin käyttö tekoälytallennuksessa
The Register -lehden mukaan flashia pidetään matalan viiveensä ja korkean suorituskyvyn ansiosta tämän hetken optimaalisimpana ratkaisuna tekoälytallennukseen. Paljon riippuu tosin myös tavasta, jolla tallennusalijärjestelmä toteutetaan. Yleensä levyryhmän viive voi olla kymmeniä millisekunteja, kun taas flashissa viive on tyypillisesti kymmeniä mikrosekunteja eli noin tuhat kertaa nopeampi. Näitä huomattavasti suurempia käsittelynopeuksia tarvitaan useimpien tekoäly- ja ML-käyttötapausten edellyttämien tehtävien suorittamiseen.
Flash tuo tallennusratkaisuna useita etuja tekoäly- ja ML-sovelluksiin. Flashin kyky hallita suurta tiedonsiirtonopeutta erittäin pienellä viiveellä tarkoittaa, että sovellus voi käyttää ja käsitellä tietoja nopeammin ja käsitellä useita pyyntöjä samanaikaisesti. Flash-tallennustilan suunnittelu – kun verrataan perinteisiin kiintolevyihin – mahdollistaa tietojen käsittelyn paljon nopeammin, koska vie täsmälleen sama aika lukea data sirun jokaisesta osasta toisin kuin kiintolevyissä, joissa levyn pinnan pyöriminen ja luku/kirjoituspäiden siirtämiseen levyn oikeaan kohtaan aiheuttaa vaihtelevia viivästyksiä.
Lisäksi, kuten The Register kirjoittaa, flash-tallennus kuluttaa myös vähemmän virtaa, mikä voi alentaa kustannuksia niille yrityskäyttäjille, jotka tarvitsevat laajamittaisia tallennusratkaisuja.
NVMe SSD -asemat ovat optimaalinen valinta AI- ja ML-palvelimille verrattuna SATA-väyläisiin SSD-asemiin. NVMe-tallennus välttää SATA-levyjen pullonkaulan yhdistämällä PCIe-väylät suoraan tietokoneen suorittimeen. NVMe-pohjainen asema voi kirjoittaa levylle jopa 4 kertaa nopeammin ja hakuajat ovat jopa 10 kertaa nopeampia. NVMe SSD -asemilla on optimoidut luku/kirjoituspyynnöt. SATA-asemat tukevat yksittäistä I/O-jonoa, jossa on 32 merkintää. NVMe-pohjaiset SSD-asemat tukevat useita I/O-jonoja, joiden teoreettinen enimmäismäärä on 64 000 jonoa, joista kukin sallii 64 000 merkintää, siis yhteensä 4,096 miljardia merkintää. NVMe-aseman ohjainohjelmisto on myös suunniteltu luomaan ja hallitsemaan I/O-jonoja. (Lähde: Computer Weekly, elokuu 2019, How to deploy NVMe flash storage for artificial intelligence).
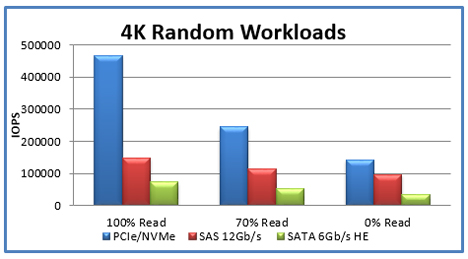
Kuva 3. SATA- ja NVMe-pohjaisen SSD:n suorituskykyjen vertailu satunnaisissa 4K-työkuormissa (Lähde: https://itpeernetwork.intel.com/why-you-should-care-about-nvm-express/#gs.9h7yfs).
Alla olevaan taulukkoon on koottu joissakin yleisimmissä AI-palvelimissa käytettyjen muistien ja tallennusratkaisujen tyyppejä ja kapasiteetteja.
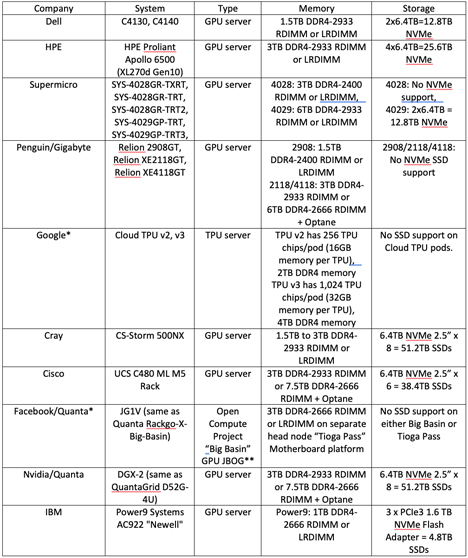
*Huomaa: Hyperskaalaluokan operoijat kuten Facebook ja Google erottavat usein laskennan ja tallennuksen dedikoituihin elementteihinsä.
**JBOG tarkoittaa ”Just a Bunch of Graphic Cards” or ”Just a Bunch of GPUs” eli ”joukkoa grafiikkakortteja” tai ”joukkoa grafiikkaprosessoreita”. Termi on hyvin samankaltainen kuin JBOD tallennuksessa, jolloin se viittaa joukkoon levyjä (”Just a Bunch of Disks”).
Tekoäly- ja koneoppimissovellusten suunnittelijat saavat hyvin tukea, jonka avulla harkita sovelluksiinsa sisällytettyjen muistin ja tallennusratkaisujen ratkaisuja. Oikeiden ratkaisujen käyttäminen voi tehdä eron sovelluksen suorituskyvyn tai epäonnistumisen tai jopa suorituskyvyn ja optimaalisen suorituskyvyn välillä, kun yritetään vastata sovelluksen ja sen käyttäjien vaatimuksiin. Tärkeintä on muistaa, että muistin ja tallennustilan on suoritettava "syöttäminen, muuntaminen ja päättäminen" -operaatiot mahdollisimman nopeasti. Tämä voi viime kädessä ratkaista, onnistuuko sovellus vai ei.














 Suuren nopeuden Ethernet-muuntajien tulee täyttää nykyaikaisille, tehokkaille verkkolaitteille asetetut vaatimukset. Niiden tehtävänä on turvata luotettava ja varma datansiirto, optimoida signaalin laatu ja tehostaa verkon yleistä suorituskykyä ja kapasiteetin hyödyntämistä.
Suuren nopeuden Ethernet-muuntajien tulee täyttää nykyaikaisille, tehokkaille verkkolaitteille asetetut vaatimukset. Niiden tehtävänä on turvata luotettava ja varma datansiirto, optimoida signaalin laatu ja tehostaa verkon yleistä suorituskykyä ja kapasiteetin hyödyntämistä.