Palvelinkeskusten kannattaisi hyödyntää pysyväismuistia tekoälyyn ja koneoppimiseen perustuvien sovellusten pullonkaulojen poistamiseksi ja suorituskyvyn parantamiseksi. Hyperkonvergoituun arkkitehtuuriin perustuva NVDIMM-moduuliratkaisu tarjoaa tähän tehokkaan välineen.
Palvelinkeskusten kannattaisi hyödyntää pysyväismuistia tekoälyyn ja koneoppimiseen perustuvien sovellusten pullonkaulojen poistamiseksi ja suorituskyvyn parantamiseksi. Hyperkonvergoituun arkkitehtuuriin perustuva NVDIMM-moduuliratkaisu tarjoaa tähän tehokkaan välineen.
Artikkelin kirjoittaja Arthur Sainio on SMART Modular Technologiesin  tuotemarkkinoinnin johtaja. Hän vastaa uusien teknologioiden kuten MRAM- ja NVDIMM-muistien kehittämisestä IIoT-, tietoliikenne-, ilmailu- ja puolustussovelluksiin. Ennen SMART Modular Technologiesin palvelukseen siirtymistään hän toimi markkinointijohtajana Hitachi Semiconductorilla. Arthurilla on tutkinnot San Francisco State- ja Arizona State -yliopistoista. tuotemarkkinoinnin johtaja. Hän vastaa uusien teknologioiden kuten MRAM- ja NVDIMM-muistien kehittämisestä IIoT-, tietoliikenne-, ilmailu- ja puolustussovelluksiin. Ennen SMART Modular Technologiesin palvelukseen siirtymistään hän toimi markkinointijohtajana Hitachi Semiconductorilla. Arthurilla on tutkinnot San Francisco State- ja Arizona State -yliopistoista. |
Nykyisten datakeskusten rajallinen keskusmuistikapasiteetti ja massamuistien kehno I/O-suorituskyky ovat kaksi eniten toimintaa rajoittavaa pullonkaulaa. Näitä kahta kipupistettä on historiallisesti pidetty erillisinä tietotekniikan käsitteinä: keskusmuisti on koodin ja datan väliaikainen varasto käynnissä olevan sovelluksen tukemiseksi, kun taas levyt ja muut pysyvät tallennustilat säilyttävät tietoja pitkillä aikaväleillä. Kun sovelluksen on käytettävä tietoja levyltä (mitä tapahtuu usein suurilla tietojoukoilla, joita ei voida pitää käyttömuistissa), hidas hakuaika heikentää merkittävästi sovelluksen suorituskykyä.
Uudentyyppisen pysyväismuistin (Persistent Memory) käyttöönotto on merkinnyt käännekohtaa perinteisten datakeskusten muistirakenteissa ja tallennushierarkiassa. Se perustuu hyperkonvergoituun arkkitehtuuriin, joka parantaa dramaattisesti tallennuspalvelimien suorituskykyä.
Tekoäly ja koneoppiminen rajussa kasvussa
Datamäärien räjähdysmäinen kasvu on johtanut tekoälyyn (AI) ja koneoppimiseen (ML) perustuvien sovellusten valtavaan kasvuun. Perinteisiä järjestelmiä ei kuitenkaan ole suunniteltu vastaamaan haasteeseen, jota massiivisiin tietojoukkoihin pääsy vaatii. IT-järjestelmien valtavirtaan siirtyvien AI- ja ML-sovellusten hankalin ongelma on tarve lyhentää tiedon löytämisen ja omaksumisen kokonaisaikaa, joka koostuu dataintensiivisen ETL-prosessin (Extract, Transform, Load) ja tallennuspisteiden määrityksen aiheuttamasta kuormituksesta.
Tekoäly ja koneoppiminen luovat erittäin kovat vaatimukset I/O- ja laskentaoperaatioiden suorituskyvylle, josta vastaa GPU-suorittimilla kiihdytetty ETL-prosessi. Vaihteleva I/O- ja laskentasuorituskyky riippuu järjestelmän kaistanleveydestä ja latenssista. Tekoäly- ja ML-sovellusten tarvitsema korkean suorituskyvyn data-analyysi vaatii järjestelmän, jolla on mahdollisimman suuri kaistanleveys ja alhainen latenssi.
IDC-tutkimusyhtiön (International Data Corporation) julkaiseman tekoälyn käyttöä koskevan raportin (Worldwide Artificial Intelligence Spending Guide) mukaan tekoälyä ja koneoppimista hyödyntäviin järjestelmiin käytettävät menot kasvavat 97,9 miljardiin dollariin vuoteen 2023 mennessä, mikä tarkoittaa kasvua yli 2,5-kertaiseksi viidessä vuodessa. Tämän laajenemisen edellyttämän laskentatehon on vastaavasti kyettävä pitämään yllä yhtä rajua kasvua.
Tavanomaisista keskusmuistiratkaisuista kuitenkin puuttuu tällä hetkellä elintärkeä komponentti, joka voi vastata tähän tarpeeseen: tallennusten pysyvyys, vaikka rinnakkaismuotoisia arkkitehtuureja jatkuvasti kehitetäänkin vastaamaan tulevaisuuden kasvaviin datatarpeisiin. Arkkitehtuureja hiotaan, mutta samaan aikaan järjestelmissä syntyvät tehohäviöt voivat maksaa datakeskuksille miljoonia dollareita. Tämä on synnyttänyt välittömän tarpeen haihtumattomille muistiratkaisuille.
Haihtumaton muisti lähemmäs CPU:ta
Tallennuspisteiden määritys on prosessi, jossa opetettavan verkon tila tallennetaan sen varmistamiseksi, että opitun tiedon tuloksia ei menetetä. Tämä on erityinen haaste tekoälyä ja koneoppimista hyödyntäville sovelluksille, koska prosessissa haaskataan suorituskapasiteettia ja käytetään paljon sähkötehoa tarjoamatta mitään etua itse sovellukselle. Datankäsittely muissa solmuissa saatetaan myös pysäyttää silloin, kun tietoja tallennetaan keskusmuistiin. Operaatio on myös hyvin kirjoitusintensiivinen, mikä pahentaa ongelmaa monissa tilanteissa, koska kiintolevyjen kaltaiset perinteiset muistiratkaisut toimivat tehottomasti, kun niihin kirjoitetaan dataa.
Koska keskusmuistin tallennuspisteiden määritys voi merkittävästi alentaa tekoäly- ja ML-sovellusten oppimisnopeutta, suunnittelijat haluavat siirtää haihtumatonta muistia entistä lähemmäs CPU:ta minimoidakseen tämän välttämättömän prosessin vaikutukset. Näin voidaan päästä parempaan tasapainoon datan ja laskennan välillä, jolloin järjestelmä pystyy paremmin vastaamaan toiminnan yleisiin tarpeisiin.
NVDIMM-muistit AI- ja ML-sovelluksissa
Haihtumattomaan muistitekniikkaan perustuvaa NVDIMM-muotoista (Non-Volatile Dual-Inline Memory Module) pysyväismuistia voidaan käyttää kirjoitusviiveensuhteen herkkien sovellusten suorituskyvyn parantamiseen tarjoamalla käyttöön pysyvän tallennuksen muistirakenne, joka yltää DRAM-muistien suorituskykyyn. Palvelinkeskuksilla on ainutlaatuinen mahdollisuus hyödyntää NVDIMM-moduuleja saavuttaakseen AI- ja ML-sovellusten vaatimat alhaiset viiveet ja tiukat suorituskykyvaatimukset ilman merkittäviä teknisiä ongelmia.
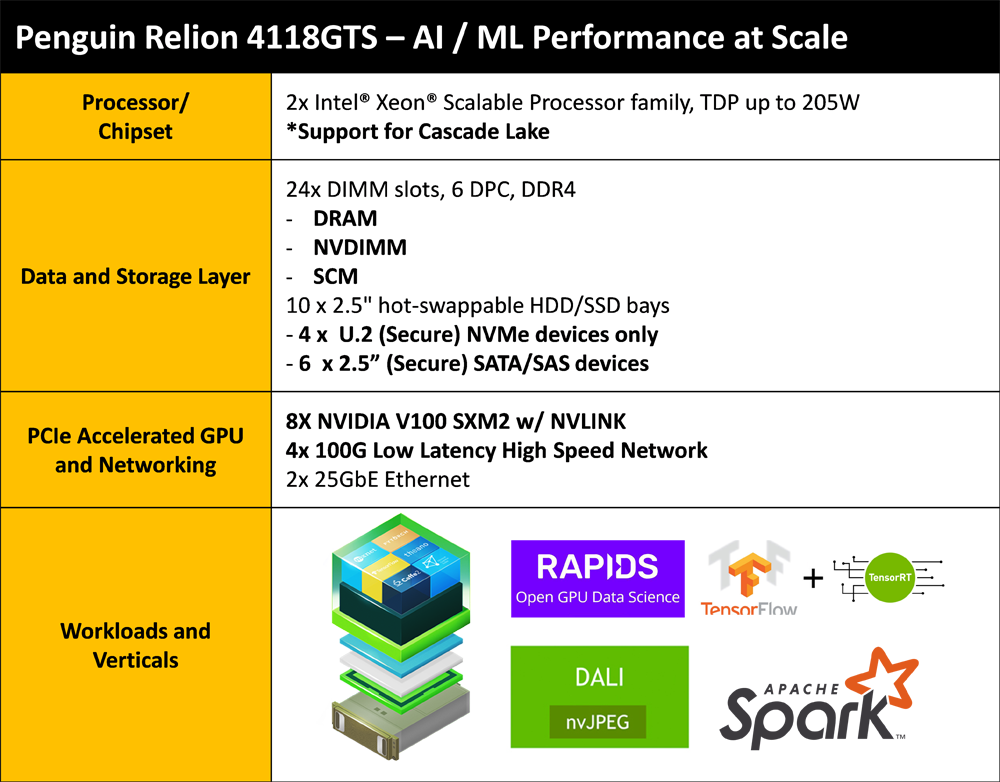
Kuva 1. Esimerkki pysyväismuistin käyttöön optimoidusta palvelimesta, joka sopii tekoälyä ja koneoppimista hyödyntäviin sovelluksiin.
Kun NVDIMM-moduulit kytketään palvelimeen, BIOS kartoittaa ne päämuistiin kuuluvana pysyväismuistin osiona. Sen jälkeen sovellus voi vapaasti käyttää tätä pysyväismuistia tallennuspisteiden nopeaan määritykseen. Vaihtoehtona olisi perinteinen lähestymistapa, jossa tallennuspisteiden tiedot siirretään I/O-pinon kautta NVMe-lohkon läpi ja tallennetaan SSD-lohkoon. Tämä järjestely lisää kuitenkin merkittävästi I/O-pinon ja NAND-flash-lohkon aiheuttamaa latenssia.
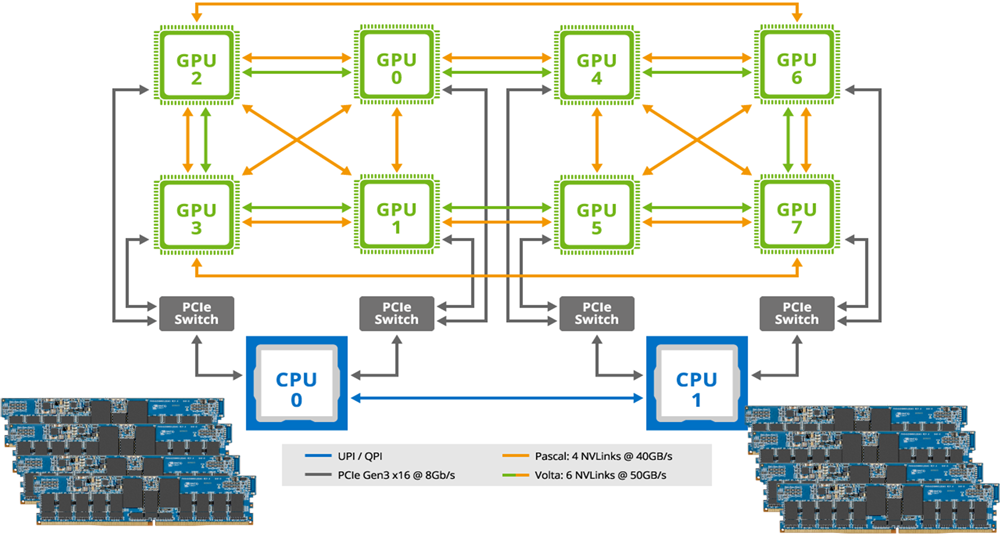
Kuva 2. Kullekin suorittimelle on varattu neljä 32 gigatavun NVDIMM-moduulia, jotka yhdessä muodostavat nopean tavuosoitettavan pysyväismuistin.
NVDIMM-moduuli on ihanteellinen ratkaisu tehokkaisiin AI- ja ML-palvelimiin. Dataintensiivisten ETL-toimintojen ja tallennuspisteiden määrityksen aiheuttamat kuormitukset voivat hyödyntää päämuistin sisältämää pysyvää muistialuetta, jolloin ne voivat toimia DRAM-muistien suoritustasolle yltävillä latensseilla (<100 ns) ja kaistanleveyksillä (25,6 GB/s).
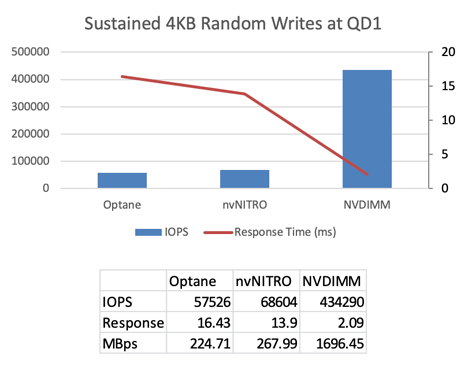
Kuva 3. Tulokset haihtumattomien muistien ezFIO-vertailutestistä, jossa olivat mukana Intel Optane NVMe 2,5 ”SSD, MRAM NVMe U.2 SSD ja NVDIMM-psysyväismuisti.
NVDIMM-moduuleja käytetään nopeuttamaan tekoälysovellusten tallennuspisteiden määrittämistä, mutta niitä voidaan käyttää myös koneoppimista hyödyntävissä sovelluksissa suorituskyvyn parantamiseen ja algoritmien keräämien tietojen suojaamiseen. GPU-ytimiin perustuvat tallennuspalvelimet suorittavat algoritmeja, jotka ovat osa simulointia ja koneoppimista. NVDIMM-moduuleja voidaan käyttää suojaamaan GPU-pohjaisia palvelimia simulaatiotietojen menettämiseltä.
Algoritmien keräämien tietojoukkojen koot vaihtelevat yleensä kilotavuista (kB) teratavuihin (TB), ja kadonneet tiedot aiheuttaisivat tarpeen aloittaa työ uudelleen. Kun neljä palvelinta on konfiguroitu NVDIMM-moduuleilla, enintään yhden teratavun kokoiset tietojoukot voivat käyttää pysyväismuistia perinteisen tallennustilan sijasta parantamaan suorituskykyä dramaattisesti ilman riskiä tietojen menetyksestä.
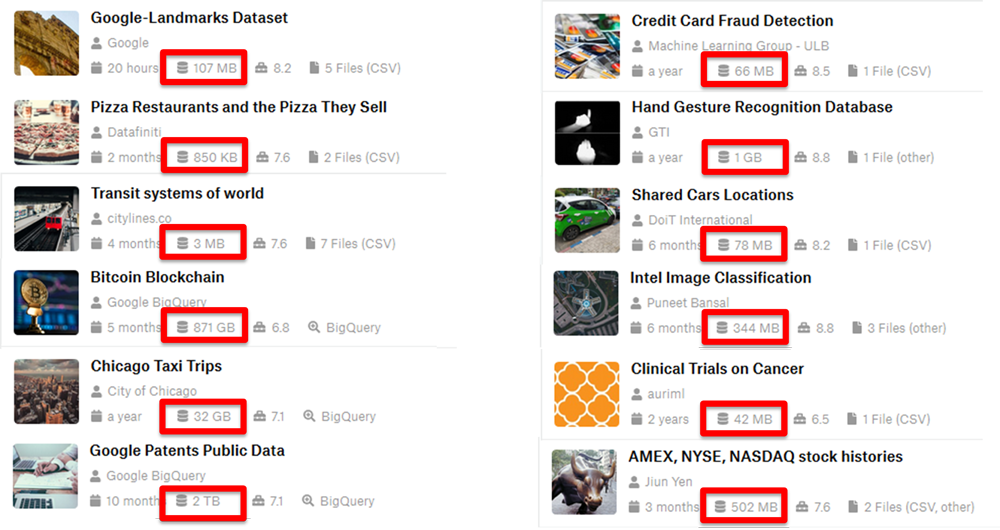
Kuva 4. Esimerkkejä koneoppimisen tietojoukoista, joiden koot vaihtelevat 850 kilotavusta kahteen teratavuun.
Yleisin menetelmä tekoälyä ja koneoppimista hyödyntävien sovellusten tuottamien simulaatiotietojoukkojen (joilla on samanlaiset ominaisuudet) käsittelemiseksi on, että tietojoukot tuodaan verkosta InfiniBand- tai Ethernet-väylän kautta AI/ML-palvelimelle ja tallennetaan sitten SSD-välimuistiin datan häviämisriskin eliminoimiseksi. GPU siirtää sen jälkeen tietojoukon osat DRAM-muistiin, jossa laskenta voidaan suorittaa. Tyypillinen esimerkki tästä prosessista voisi olla laskennan suorittaminen tietojoukolle sen selvittämiseksi, edustavatko tiedot kuvaa kissasta vai koirasta. Kun laskenta on valmis, vastaus lähetetään takaisin verkkoon. Jos järjestelmä kaatuu prosessin aikana, kaikki laskelmat menetetään.
Vaihtamalla muistiratkaisu NVDIMM-moduuleihin tätä prosessia voidaan dramaattisesti virtaviivaistaa. Saapuvia tietojoukkoja ei tarvitse tallentaa SSD-välimuistiin, vaan ne voidaan siirtää suoraan DRAM-muistiin, jossa GPU voi heti aloittaa laskutoimitukset. Vastaus siihen, edustaako tietty tietojoukko kuvaa koirasta vai kissasta, voidaan näin saada useita kertaluokkia nopeammin. Silloin ei myöskään ole vaaraa tietojoukkojen tai laskelmien menettämisestä, koska NVDIMM on pysyväismuisti.
AI- ja ML-sovellusten lisäksi NVDIMM-moduuleja voidaan hyödyntää myös finanssialalle tarkoitetuissa FinTech-sovelluksissa. Ne vaativat korkeaa suorituskykyä (viiveiden lyhentämiseen ja transaktionopeuksien lisäämiseen), sillä finanssipuolella aika on rahaa. Käsitellyt tapahtumat on kirjattava ylös synkronisesti ennen seuraavan tapahtuman aloittamista. Tämä synkronointitoiminto on välttämätön tilinpidon kannalta, mutta se luo myös merkittävän pullonkaulan järjestelmään hidastamalla tapahtumien etenemisnopeutta.
NVDIMM-moduuleja käyttämällä voidaan välttää tavanomainen tietojen kirjaaminen SATA- tai NVMe SSD -asemiin. Sen sijaan, että lokitiedot lähetettäisiin I/O:n kautta Flash SSD:lle, ne voidaan sijoittaa suoraan huippunopeaan DRAM-muistiin, josta on muodostettu pysyväismuisti NVDIMM-moduulien avulla. Niiden ansiosta järjestelmä voi aina aloittaa seuraavan tapahtuman luottaen siihen, että edellinen tapahtuma on kirjattu turvalliseen paikkaan ilman riskiä tietojen menettämisestä.
Vaikka NVDIMM-moduuleja on ollut saatavilla jo vuosia, monilla eri sektoreilla tutkitaan jatkuvasti tämän tyyppisen pysyväismuistin hyödyntämistä AI- ja ML-sovelluksissa: pankkimaailmassa, vähittäiskaupassa, prosessiteollisuudessa, terveydenhuollossa, ammattitason palvelujärjestelmissä jne.
NVDIMM-moduulien tukema ekosysteemi, johon kuuluvat käyttöjärjestelmät, laitteiden käyttöönotto ja JEDEC-standardointi, on seurausta siitä, että lukuisat yritykset ovat tehneet yhteistyötä pysyväismuistin ottamiseksi käyttöön eri järjestelmissä. NVDIMM-ratkaisut tukevat tekoälyä ja koneoppimista hyödyntävien sovellusten yleistymistä tarjoamalla ihanteellisen tavan parantaa järjestelmien suorituskykyä.

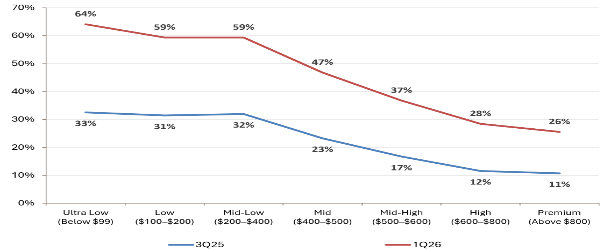
 Tekoäly on jo selkeästi ohittanut kokeiluvaiheen. Avnet Insights 2026 -selvityksen mukaan tekoäly on monilla elektroniikan aloilla jo mukana käytössä olevissa tuotteissa, ja sen soveltaminen yleistyy nopeasti kaikkialla EMEA-alueella.
Tekoäly on jo selkeästi ohittanut kokeiluvaiheen. Avnet Insights 2026 -selvityksen mukaan tekoäly on monilla elektroniikan aloilla jo mukana käytössä olevissa tuotteissa, ja sen soveltaminen yleistyy nopeasti kaikkialla EMEA-alueella.










 <
<