











Big data on otsikoissa tänään, mutta myös Small data on tärkeää. Pienten datakoosteiden, kuten harvinaisten sairauksien kliinisten tutkimusten tai uhanalaisten lajien tutkimuksissa, luotettavien johtopäätösten tekeminen on edelleen yksi kaikkein vaikeimmista esteitä tilastoinnissa.
Epävarmuus, joka liittyy pieniin data-aineistoihin, on turhauttanut fyysikoita, kliinikoita ja jopa ekologeja vuosikymmeniä. Nyt Cold Spring Harbor Laboratoryn (CSHL) tutkijat ovat suunnitelleet laskennallisen lähestymistavan, joka saattaa ratkaista tämän varsin yleisen ongelman.
- Pienien datakoosteiden käsittely on olennainen osa tieteen tekemistä, selvittää CSHL:n apulaisprofessori Justin Kinney. Haasteena on, että hyvin vähästä datasta ei ole ainoastaan vaikea päätyä johtopäätöksiin. On myös vaikea määrittää, miten varmoja tietyt johtopäätökset ovat.
- On tärkeätä paitsi tuottaa paras arvaus siitä, mitä tapahtuu, mutta myös sanoa: Tämä arvaus on luultavasti oikea, sanoi Kinney.
Hyvä esimerkki ovat yksittäisten potilaiden kliiniset lääketutkimukset. Niissä on todella tärkeää, että päätökset tehdään mahdollisimman pienillä datakoosteilla.
Kinneyn laboratorion kehittämä laskennallisen lähestymistavan nimi on Density Estimation unsing Field Theory tai DEFT. Se on nyt vapaasti käytettävissä avoimen lähdekoodin pakettina nimellä SUFTware.
Tutkimusjulkaisussaan Kinneyn laboratorio demonstroi DEFT:ä kahdella datakoosteella: Maailman terveysjärjestön laatima kansallinen terveysstatistiikka sekä Large Hadron Colliderin fyysikkojen käyttämät subatomisten hiukkasten radat paljastamassa Higgsin bosonin hiukkasen olemassaoloa. Kinney toteaa, että kyvyt soveltaa DEFT:ä tällaisiin dramaattisesti erilaisiin todellisiin tilanteisiin tekee uuden lähestymistavan tehokkaaksi.
Veijo Hänninen
Nanobittejä 23.10.2018
 Tekoäly-PC suorituskyky ei riipu vain prosessorista, grafiikkapiiristä tai NPU-kiihdyttimestä. Kun paikalliset kielimallit ja tekoälyagentit kasvavat, pullonkaulaksi voi nousta myös tallennus. Silicon Motion vastaa tähän uudella SM2524XT-ohjainpiirillä, joka on suunnattu PCIe Gen5 -SSD-levyihin.
Tekoäly-PC suorituskyky ei riipu vain prosessorista, grafiikkapiiristä tai NPU-kiihdyttimestä. Kun paikalliset kielimallit ja tekoälyagentit kasvavat, pullonkaulaksi voi nousta myös tallennus. Silicon Motion vastaa tähän uudella SM2524XT-ohjainpiirillä, joka on suunnattu PCIe Gen5 -SSD-levyihin.
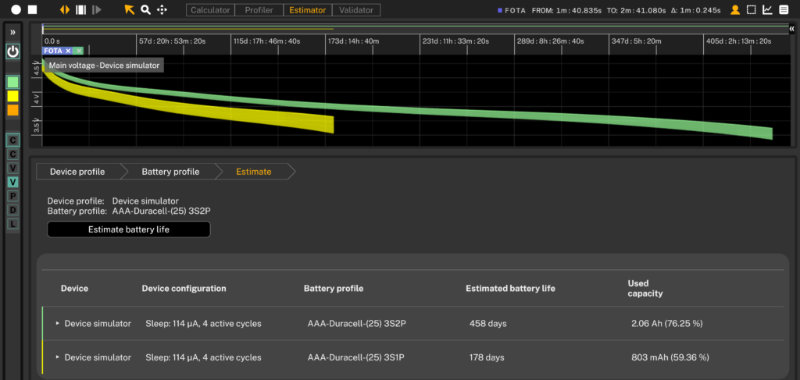



















 Tekoäly, kehittyneet yhteydet ja tietoturva muuttavat sulautettujen järjestelmien arkkitehtuureja. Laskentateho kasvaa nopeasti samaan aikaan, kun laitteiden fyysinen koko pienenee. Tietoturva, datan hallinta ja uudet säädökset lisäävät vaatimuksia niin yhteyksille kuin suunnittelullekin. Samalla laitevalmistajat pyrkivät nopeuttamaan tuotekehitys- ja testaussyklejään.
Tekoäly, kehittyneet yhteydet ja tietoturva muuttavat sulautettujen järjestelmien arkkitehtuureja. Laskentateho kasvaa nopeasti samaan aikaan, kun laitteiden fyysinen koko pienenee. Tietoturva, datan hallinta ja uudet säädökset lisäävät vaatimuksia niin yhteyksille kuin suunnittelullekin. Samalla laitevalmistajat pyrkivät nopeuttamaan tuotekehitys- ja testaussyklejään.