










 Tekoälyn yleistyminen kaikkien saataville asettaa uusia haasteita sulautettujen järjestelmien suunnittelijoille. Tämä koskee erityisesti verkon reunalla toimivia, koneoppimista (ML) hyödyntäviä IoT-sovelluksia. Niiden on toimittava hyvin tehokkaasti mahdollisimman alhaisella syöttövirralla sekä täytettävä prosessorien ja muistien vähimmäisvaatimukset.
Tekoälyn yleistyminen kaikkien saataville asettaa uusia haasteita sulautettujen järjestelmien suunnittelijoille. Tämä koskee erityisesti verkon reunalla toimivia, koneoppimista (ML) hyödyntäviä IoT-sovelluksia. Niiden on toimittava hyvin tehokkaasti mahdollisimman alhaisella syöttövirralla sekä täytettävä prosessorien ja muistien vähimmäisvaatimukset.
| Yann LeFaou toimii johtajana Microchipin kosketus- ja eleohjaustekniikan liiketoimintayksikössä. Tässä roolissa LeFaou johtaa kapasitiivisia kosketustekniikoita kehittävää tiimiä ja edistää myös yhtiön koneoppimishankkeita (ML) mikro-ohjaimille ja prosessoreille. Hän on toiminut yhtiössä pitkään useissa teknisissä ja markkinointitehtävissä, mukaan lukien kapasitiivisen kosketustekniikan, ihmisen ja koneen rajapinnan sekä kodinteknologian globaalin markkinoinnin johtaminen. LeFaoulla on tutkinto ranskalaisesta ESME Sudria -oppilaitoksesta. |
Koneoppimismallien ympärille rakennettu tekoäly (AI) on yleistymässä teollisen internetin reunalaskennan monissa sovelluksissa: valvonnassa, pääsynhallinnassa, älykkäissä tehtaissa, ennakoivassa kunnossapidossa. Tämän yleistymisen myötä tekoälyratkaisujen rakentaminen on ’demokratisoitunut’ eli siirtynyt datatieteilijöiden erikoisalasta sellaiseksi, jota sulautettujen järjestelmien suunnittelijoiden odotetaan ymmärtävän.
Tämän kehityksen haasteena on, että suunnittelijat eivät välttämättä ole riittävän valmistautuneita määrittelemään ratkaistavaa ongelmaa sekä tallentamaan ja organisoimaan dataa mahdollisimman sopivalla tavalla. Lisäksi, toisin kuin kuluttajapuolella, teollisen tekoälyn toteutuksiin on saatavissa vain vähän valmiita datajoukkoja, joten ne on usein luotava itse käyttäjän omista tiedoista.
Mukaan valtavirtaan
Tekoäly on jo siirtynyt valtavirtaan, ja syväoppiminen (DL) sekä koneoppiminen (ML) ovat monien nykyään itsestäänselvyyksinä pidettyjen sovellusten taustalla. Näitä ovat esimerkiksi luonnollisen kielen käsittely, konenäkö, ennakoiva kunnossapito ja datanlouhinta.
Tekoälyn varhaiset toteutukset ovat olleet pilvi- tai palvelinpohjaisia. Ne ovat myös vaatineet paljon prosessointitehoa ja tallennustilaa sekä suurta kaistanleveyttä AI/ML-sovelluksen ja verkon reunalla toimivan laitteen (endpoint) välillä. Vaikka tällaisia järjestelyjä tarvitaan edelleen generatiivisissa tekoälysovelluksissa (ChatGPT, DALL-E, Bard), viime vuosina saataville on tullut myös reunalaskentaan soveltuva AI, jossa dataa käsitellään reaaliaikaisesti sen tallennuspisteessä.
Reunalaskenta vähentää merkittävästi riippuvuutta pilvestä, nopeuttaa koko järjestelmää ja sovellusta, vaatii vähemmän virtaa ja alentaa kustannuksia. Monet pitävät myös sen turvallisuutta parempana. Tarkemmin ilmaistuna turvallisuuden painopiste siirtyy pilven ja päätepisteen välisen viestinnän suojaamisesta reunalaitteen turvallisuuden parantamiseen.
Reunalaskennassa tekoäly/koneoppiminen voidaan toteuttaa perinteisissä sulautetuissa järjestelmissä, joiden suunnittelijoilla on käytössään tehokkaat mikroprosessorit, graafiset suoritinyksiköt ja runsaasti muistilaitteita - resurssit vastaavat PC-maailman resursseja. AI/ML-reunalaskentaa hyödyntäville (kaupallisille ja teollisille) IoT-laitteille on kuitenkin kasvava kysyntä, ja niillä on käytettävissään tyypillisesti hyvin rajalliset laiteresurssit. Monissa tapauksissa laitteet ovat lisäksi akkukäyttöisiä.
Resurssi- ja tehorajoitteisilla laitteilla toimivan tekoälyn/koneoppisen mahdollisuus toimia verkon reunalla on synnyttänyt alueelle konseptin TinyML. Esimerkkejä sen käytöstä on jo nähtävissä runsaasti teollisuudessa (ennakoiva kunnossapito), taloautomaatiossa (ympäristön valvonta), rakentamisessa (henkilöturvan valvonta) sekä turvallisuuspalveluissa.
Työnkulun datavuo
AI (ja sen osajoukko ML) vaatii kuvauksen työnkulusta aina datankeruusta mallin käyttöönottoon asti (kuva 1). TinyML:n osalta optimointi työnkulun jokaisessa vaiheessa on olennaista sulautetun järjestelmän rajallisten resurssien vuoksi.
TinyML:n resurssivaatimuksina pidetään 1 – 400 MHz prosessointinopeutta, 2 – 512 kilotavua RAM-muistia ja 32 kB – 2 MB tallennustilaa (flash). Lisäksi 150 µW – 23,5 mW tehoalueella toimiminen näin pienellä tehobudjetilla osoittautuu usein haastavaksi.

Kuva 1. Yksinkertaistettu kaavio tekoälyn työnkulusta. Vaikka tässä kaaviossa ei asiaa ole esitetty, mallin käyttöönottovaiheen on itse syötettävä dataa takaisin työnkulkuun, mikä voi jopa vaikuttaa datan keräämiseen.
Lisäksi tekoälyn sulauttamiseen resurssirajoitteisiin järjestelmiin liittyy merkittävä seikka tai pikemminkin kompromissi, joka on otettava huomioon. Mallit ovat ratkaisevan tärkeitä järjestelmän käyttäytymiselle, mutta suunnittelijat joutuvat usein tekemään kompromisseja mallin laadun ja tarkkuuden välillä. Tämä vaikuttaa järjestelmän luotettavuuteen ja toimintavarmuuteen sekä suorituskykyyn – pääasiassa kuitenkin toimintanopeuteen ja virrankulutukseen.
Toinen keskeinen tekijä on mukaan valittavan tekoälyn tai koneoppimisen tyyppi. Yleensä tarjolla on kolmenlaisia algoritmeja, joita voidaan käyttää: valvottuja, valvomattomia ja vahvistettuja.
Käytännön ratkaisut
Jopa tekoälyä ja koneoppimista hyvin ymmärtävillä suunnittelijoilla voi olla vaikeuksia optimoida AI/ML-työnkulun jokaista vaihetta ja löytää täydellinen tasapaino mallin tarkkuuden ja järjestelmän suorituskyvyn välille. Miten sulautettujen järjestelmien suunnittelijat, joilla ei ole aiempaa kokemusta, voivat sitten vastata haasteisiin?
Ensinnäkin on tärkeää pitää mielessä, että resurssirajoitteisiin IoT-laitteisiin sijoitetut mallit ovat tehokkaita vain, jos malli on kooltaan pieni ja tekoälyn tehtävä rajoittuu yksinkertaisen ongelman ratkaisemiseen.
Onneksi koneoppimisen (ja erityisesti TinyML:n) saapuminen sulautettujen järjestelmien alueelle on johtanut uusiin (tai paranneltuihin) IDE-ympäristöihin (Integrated Development Environment), ohjelmistotyökaluihin, arkkitehtuureihin ja malleihin – joista monet ovat avoimen lähdekoodin tuotteita.
Esimerkiksi mikro-ohjaimia varten kehitetty TensorFlow Lite (TF Lite Micro) on ilmainen avoimen lähdekoodin ohjelmistokirjasto ML/AI-sovelluksia varten. Se on tarkoitettu ML-toteutuksiin laitteilla, joissa on vain muutama kilotavu muistia. Ohjelmia voidaan kirjoittaa myös Python-kielellä, joka sekin on ilmainen avoimen lähdekoodin tuote.
IDE-ympäristöjen osalta Microchipin MPLAB X on esimerkki tällaisesta ohjelmointiympäristöstä. Sitä voidaan käyttää yhdessä MPLAB ML -suunnittelupaketin kanssa. Kyseessä on MPLAB X -laajennus, joka on kehitetty erityisesti AI-pohjaisille IoT-antureille optimoitujen tunnistuskoodien luomiseksi.
AutoML-prosessiin perustuva MPLAB ML automatisoi täysin tekoälyn ML-työnkulun jokaisen vaiheen, mikä poistaa tarpeen toistuvalle, työläälle ja aikaa vievälle mallin rakentamiselle. Ominaisuuksien määritys, mallin koulutus, validointi ja testaus varmistavat optimoidut mallit, jotka täyttävät mikro-ohjaimien ja prosessorien sanelemat muistirajoitukset. Kehittäjät voivat näin luoda ja ottaa nopeasti käyttöön koneoppimisratkaisuja Microchipin Arm Cortex -pohjaisilla mikro-ohjaimilla tai prosessoreilla.
Vuon optimointi
Työnkulun optimointitehtäviä voidaan yksinkertaistaa aloittamalla valmiilla datajoukoilla ja malleilla. Jos esimerkiksi koneoppimista tukeva IoT-laite tarvitsee kuvantunnistusta, on järkevää mallin kouluttamiseksi (testaus, evaluointi) aloittaa datajoukosta, joka koostuu nykyisistä nimiöidyistä staattisista kuvista ja videoleikkeistä. On pidettävä mielessä, että valvotut ML-mallit vaativat aina nimiöidyn datan.
Konenäkösovelluksia varten on jo olemassa paljon kuva-aineistoja. Koska ne on kuitenkin tarkoitettu PC-, palvelin- ja pilvipohjaisiin sovelluksiin, ne ovat yleensä kooltaan hyvin suuria. Esimerkiksi ImageNetin kuvatietokanta sisältää yli 14 miljoonaa kommentoitua kuvaa.
ML-sovelluksesta riippuen saatetaan tarvita vain muutamia osajoukkoja: esimerkiksi paljon kuvia ihmisistä mutta vain muutamia elottomista esineistä. Jos ML-yhteensopivia kameroita käytetään esimerkiksi rakennustyömaalla, ne voivat välittömästi antaa hälytyksen, jos kypärätön henkilö tulee niiden näkökenttään. Koneoppimismalli on koulutettava, mutta mahdollisesti käyttämällä vain muutamia kuvia ihmisistä kypärän kera ja ilman. Erilaisista päähinetyypeistä saatetaan kuitenkin tarvita laajempi datajoukko, jotta voidaan ottaa huomioon kaikki eri tekijät, muun muassa erilaiset valaistusolosuhteet.
Virheettömien reaaliaikaisten syötetietojen ja datajoukon hankkiminen, datan valmistelu ja mallin kouluttaminen muodostavat kolme ensimmäistä vaihetta kuvassa 1. Mallin optimointi (vaihe 4) on tyypillisesti datan pakkaamista, joka auttaa vähentämään muistivaatimuksia (RAM prosessoinnin aikana ja NVM tallennuksessa) sekä lyhentämään datankäsittelyn latenssia.
Datankäsittelyn osalta monet tekoälyalgoritmit (mm. konvoluutioneuroverkko CNN) kamppailevat monimutkaisten mallien kanssa. Suosittu pakkaustekniikka on karsinta (kuva 2), josta on neljä eri tyyppiä: painoarvon karsinta, yksiköiden/neuronien karsinta ja iteratiivinen karsinta.

Kuva 2. Karsinta vähentää neuroverkon tiheyttä. Joidenkin neuronien välisten yhteyksien painoarvo on tässä asetettu nollaksi. Joskus verkon neuronejakin voidaan karsia (ei näy tässä).
Kvantisointi on toinen suosittu pakkaustekniikka. Kyseessä on prosessi, jossa dataa muunnetaan erittäin tarkasta muodosta, esimerkiksi 32-bittisestä liukulukumuodosta (FP32), vähemmän tarkkaan muotoon, esimerkiksi 8-bittiseksi kokonaisluvuksi (INT8). Kvantisoitujen mallien (kuva 3) käyttöä voidaan hyödyntää koneoppimisessa kahdella tavalla:
- Koulutuksen jälkeiseen kvantisointiin kuuluu mallien käyttö esimerkiksi FP32-muodossa. Kun koulutusvaihe katsotaan suoritetuksi, kvantisointi suoritetaan käyttöä varten. Esimerkiksi standardin mukaista TensorFlow’ta voidaan käyttää mallin alustavaan koulutukseen ja optimointiin PC:llä. Malli voidaan sitten kvantisoida ja TensorFlow Liten avulla sulauttaa IoT-laitteeseen.
- Kvantisointitietoinen koulutus emuloi päättelyvaiheen kvantisointia ja luo mallin, jota jatkotyökalut käyttävät kvantisoitujen mallien tuottamiseen.
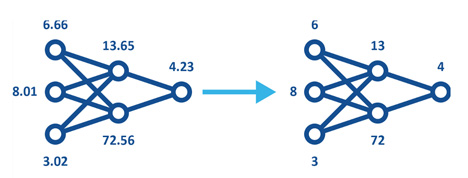
Kuva 3. Kvantisoidut mallit käyttävät alhaisempaa tarkkuutta. Tämä vähentää muisti- ja tallennusvaatimuksia sekä parantaa energiatehokkuutta, mutta säilyttää mallille saman muodon.
Vaikka kvantisointi on hyödyllistä, sitä ei pitäisi käyttää liikaa. Sitä voisi verrata digitaalisen kuvan pakkaamiseen esittämällä värejä vähemmillä biteillä ja/tai käyttämällä vähemmän pikseleitä. Eli jossain vaiheessa tulee vastaan raja, jolloin kuvaa on jo vaikea tulkita.
Haasteet hallintaan
Kuten aiemmin todettiin, tekoäly on jo tärkeä osa sulautettuja järjestelmiä. Tämä yleistyminen tarkoittaa kuitenkin sitä, että ne suunnittelijat, joiden ei aiemmin ole tarvinnut hallita tekoälyä ja koneoppimista, kohtaavat suunnittelutyössään merkittäviä haasteita AI-pohjaisten ratkaisujen toteuttamisessa.
Vaikka ML-sovellusten luominen ja rajallisten laiteresurssien hyödyntäminen voi tuntua pelottavalta, se ei varsinaisesti ole mikään uusi haaste – ainakaan kokeneille sulautettujen järjestelmien suunnittelijoille. Hyvä uutinen on se, että sulautettujen järjestelmien kehitysyhteisössä on tarjolla runsaasti tietoa (ja koulutusta), IDE-ympäristöjä (esim. MPLAB X), mallinnustyökaluja (esim. MPLAB ML) sekä valmiita avoimen lähdekoodin datajoukkoja ja malleja.
Tämä ekosysteemi auttaa erityisesti suunnittelijoita, joilla on jo jonkinasteista kehityskokemusta nopeista AI- ja ML-ratkaisuista. Nyt ne voidaan kuitenkin toteuttaa 16-bittisillä tai jopa 8-bittisillä mikro-ohjaimilla.







 <
<










 Tekoäly on jo selkeästi ohittanut kokeiluvaiheen. Avnet Insights 2026 -selvityksen mukaan tekoäly on monilla elektroniikan aloilla jo mukana käytössä olevissa tuotteissa, ja sen soveltaminen yleistyy nopeasti kaikkialla EMEA-alueella.
Tekoäly on jo selkeästi ohittanut kokeiluvaiheen. Avnet Insights 2026 -selvityksen mukaan tekoäly on monilla elektroniikan aloilla jo mukana käytössä olevissa tuotteissa, ja sen soveltaminen yleistyy nopeasti kaikkialla EMEA-alueella.