









Business Finland järjesti tänään webinaarin, jossa käsiteltiin laajoihin kielimalleihin perustuvien tekoälymallien hyödyntämistä. Kehitys on ollut nopeaa, mutta moni erityisesti eettinen kysymys on edelleen ratkaisematta.
Sääntöjä tekoälylle haetaan regulaation kautta. EU:ssa kehitetään omaa yksityishenkilöiden vapauksiin keskittyvää AI-lainsäädäntöä, Yhdysvalloissa omaansa ja Iso-Britanniassa laaditaan enemmän yritystoiminnan kannalta laadittua sääntelyään. Enne Analyticsin toimitusjohtaja Ilkka Raiskinen muistutti myös, että monet maat eivät tule reguloimaan tekoälyä ollenkaan.
LLM- eli laajoihin kielimalleihin perustuva tekoäly sisältä itse asiassa hyvin vähän älyä. - Malli ennustaa, mitkä sanat seuraavat tietyssä kontekstissa. Jokaisen sanan todennäköisyys lasketaan GPT:n tapauksessa 75 miljardin parametrin avulla.
- Tekoälyn ”äly” perustuu siihen, että se on koulutettu valtavalla määrällä tekstiä. Teksti pitää ensin muuntaa numeroiksi. Sanojen osat ja lauseet kuvataan vektoreina, jotka säilyttävät semantiikkansa, Raiskinen selitti kielimallin logiikkaa.
Pelkkä malli ei sellaisenaan riitä, vaan sitä pitää hienosäätää. - Mallille annetaan valmiita kysymys-vastauspareja, joilla esimerkiksi toksiseen sisältöön reagoidaan. Voidaan rakentaa ylimääräinen malli, joka osaa arvottaa vastauksia: toksinen vastaus voi esimerkiksi saada ison negatiivisen numeron, Raiskinen jatkoi.
Tähän sisältyy myös iso eettinen ongelma. Kuka on se auktoriteetti, joka päättää mikä on parempi, arvokkaampi, inklusiivisempi jne. - Tutkimukset osoittavat jo, että kielimallit ottavat huonosti huomioon vähemmistöjä, vanhuksia ja muita ryhmiä. Kielimalli ei ole missään tapauksessa neutraali. Lisäksi se ei ole sidoksissa maailmaan, vaan teksteihin, Raiskinen korosti.
Business Finlandin webinaarissa esitetyt demot osoittavat, että mallien hyödyntäminen palveluiden käyttöön on tullut jo varsin helpoksi. Edelleen mallien kouluttaminen maksaa, mutta GPU-farmien hinta on tulossa alas nopeaa vauhtia.
Suomessa on selvä pyrkimys rakentaa omia, avoimia LLM-malleja. Moni ei halua ostaa kaupallista mallia, koska kyse on pitkälti ”mustasta laatikosta”. Onneksi avoimien ja myös suomalaisten mallien kehitys on edennyt nopeasti. Esimerkiksi LUMI-supertietokoneessa on koulutettu TurkuNLP:n 13 miljardin parametrin Fin GPT-3 -malli, joka on vapaasti saatavissa.
LUMI-superkonetta operoivan CSC:n kumppanuuksista vastaava Dan Still kertoi, että vuoden 2024 alussa valmistuu avoin OLMo-malli, jossa on jo 70 miljardia parametria. Näyttää siis siltä, että avoimet kielimallit saavuttavat OpenAI:n kaltaisia kaupallisia malleja varsin nopeaan tahtiin.
Kelloa ei kuitenkaan voi kääntää taaksepäin. Microsoftin data- ja AI-tuotteiden kaupallistamisesta vastaava Lukas Lundin muistutti, miten Italiassa kävi, kun ChatGPT kiellettiin kahdeksi viikoksi. - Koodaajien tuottavuus putosi 50 prosenttia. Kun ChatGPT palautettiin, tuottavuus palasi vanhalle tasolla kahdessa viikossa.




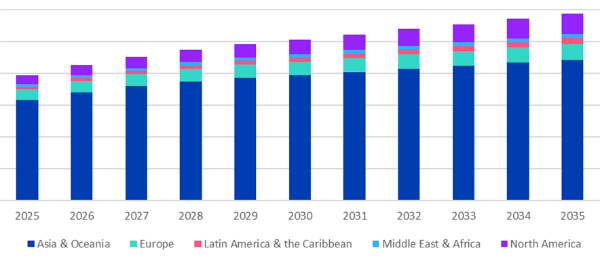










 Suuren nopeuden Ethernet-muuntajien tulee täyttää nykyaikaisille, tehokkaille verkkolaitteille asetetut vaatimukset. Niiden tehtävänä on turvata luotettava ja varma datansiirto, optimoida signaalin laatu ja tehostaa verkon yleistä suorituskykyä ja kapasiteetin hyödyntämistä.
Suuren nopeuden Ethernet-muuntajien tulee täyttää nykyaikaisille, tehokkaille verkkolaitteille asetetut vaatimukset. Niiden tehtävänä on turvata luotettava ja varma datansiirto, optimoida signaalin laatu ja tehostaa verkon yleistä suorituskykyä ja kapasiteetin hyödyntämistä.