



Kajaanissa CSC:n tiloissa majailevaa LUMI-supertietokonetta on käytetty Turun yliopiston ja Silo AI:n kehittämiin suuriin kielimalleihin kuten Poro ja Viking. CSC:n tekoälypalvelujen kehittämisestä vastaava Aleksi Kallio kertoi ECF24-tapahtumassa, miten suuria kielimalleja koulutetaan supertietokoneella.
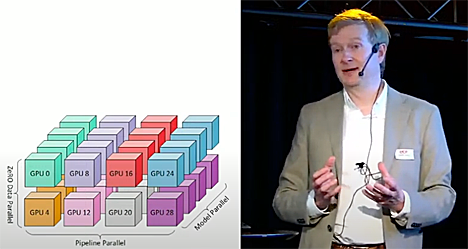
LLM-mallin koulutus on raskasta rinnakkaislaskentaa. LUMI-koneella on 2978 GPU-solmua, joissa jokaisessa on neljä AMD Instinct MI250X-prosessoria. Koska piirit ovat kaksiytimisiä, GPU-prosessoreita on käytössä yhteensä 24 tuhatta kappaletta.
Ensimmäinen LUMI-koneen laskema suomalainen kielimalli oli TurkuNLP:n FINGPT3, joka valmistui tammikuussa 2023. Se koulutettiin täysin suomalaisella materiaalilla, Aleksi Kallion mukaan käytännössä kaikella suomalaisella tekstillä, mikä oli käytettävissä. Sen sijaan yhteistyössä Silo AI:n kanssa kehitetty Poro kehitettiin pääosin englanninkielisellä datasarjoilla, jotka yhdistettiin suomalaiseen dataan.
- Englanninkielistä tekstiä on paljon enemmän, joten malli voitiin rakentaa yhdistämällä näitä kieliä. Itse asiassa englanninkielen käyttäminen paransi Poroa, sillä englanninkielessä on enemmän ymmärrystä siitä, miten käsitteet toimivat ja miten maailman toimii.
Poro on jo tavallaan historiaa ja TurkuNLP ja Silo AI työskentelevät Viking-mallin parissa. - VIkign ymmärtää kaikkia viittä pohjoismaista kieltä, englantia ja ohjelmistokoodia. Mallista on koulutettu erikokoisia versioita (7, 13 ja 33 miljardia parametria), Kallio kertoi.
LUMI-superkoneella on koulutettu myös amerikkalaisen Allen-instituutin OLMo-kielimalli, joka on 7 miljardin parametrin malli lähinnä tieteellisten tekstien analyysiin.
Miten LLM-malleja sitten koulutetaan? Malleja koulutetaan ennustamaan haluttu tuotos käyttäjän antamasta syötteestä eli promptista. Mallin esikoulutuksessa muutamia miljardeja - satoja miljardeja parametreja sisältävään neuraaliverkkoon syötetään biljoonia tokeneita - karkeasti ottaen sanoja, Kallio muistuttaa.
Malli ymmärtää myös käsitteitä kuten ajan ja tilan. - Ei voi sanoa, että malli ymmärtäisi maailmaa, mutta sillä on käytössään jonkinlainen malli siitä.
Tämä esikouluttaminen on niin laskentaintensiivinen prosessi, että se voidaan tehdä vain supertietokoneella. Näin saatua mallia viritetään pienemmällä datasarjalla, jotta se oppii noudattamaan sille laadittuja sääntöjä. Tämäkin tehdään yleensä superkoneilla.
Niinpä Poro-mallin koulutukseen kläytettiin 32 miljardia suomen kielen sanaa (tokenia), 500 miljardia tokenia englannin kieltä ja 200 miljardia tokenia ohjelmistokoodia. Data näytteistettiin niin, että suomenkielisten tokeneiden rooli korostui.
Tulokset ovat hyvin. Suomen kielessä Poro 34B on selvästi etevämpi kuin suurin piirtein samankokoinen Llama 33B ja selvästi muita avoimia malleja parempi. Englannin kielessäkin Poro pärjää kohtuullisesti, vaikka jääkin Llaman ja parin muun taakse. - Myös ohjelmakoodissa Poro pärjää hyvin, paremmin kuin Llama ja lähes yhtä hyvin kuin ohjelmakoodiin kehitetty Starcoder-malli. Erityisen hyvin Poro suoriutuu käännöksissä englannista suomeen, jopa paremmin kuin OpenAI:n GPT4.
Aleksi Kallion esitys näkyy ECF-tapahtuman Youtube-kanavalla. Esityskalvot löytyvät täältä.










