Salauksesta on tullut pakollinen tekniikka, mikäli dataa halutaan lähettää turvallisesti. 128-bittisen AES-salauksen voi toteuttaa tehokkaasti PsoC-järjestelmäpiirillä, esitetään Cypress Semiconductorsin artikkelissa.
| Artikkelin ovat kirjoittaneet Cypress Semiconductorsin Ahmed Majeed Khan, Asma Afzal ja Khawar Khurshid. Ahmed Majeed Khan on vastannut esimerkiksi tietoturvallisten magnettikorttien lukulaitteiden kehityksestä. Hänellä on elektroniikkainsinöörin tutkinto Michigan Staten yliopistosta ja yli 8 vuoden kokemus mikro-ohjaimista ja sulautetuista sovelluksista. Asma Afzal suorittaa parhaillaan elektroniikkainsinöörin tutkintoa NUST-yliopistossa (National University of Sciences and Technology) Pakistanissa. Tällä hetkellä hän optimoi erilaisia salausmentelmiä Cypressin PsoC-piireille. Khawar Khurshid toimii NUST-Cypress -tutkimuskeskuksen johtajana Pakistanin Islamabadissa. Hänellä on tohtorin tutkinto Michigan States. Tri Kurshid on erikoistunut lääketieteen kuvastamiseen, tietokonenäköön , hahmontunnistamiseen sekä kuvan ja signaalinprosessointiin. |
Yleisimmin käytetyt salaustekniikat hyödyntävät determinististä algoritmia, jossa muunnos ei vaihtele käsitellessään kiinteän mittaisia datablokkeja. Esimerkkejä tällaisista tekniikoista ovat Advanced Encryption Standard (AES), Data Encryption Standard (DES), International Data Encryption Algorithm (IDEA) ja RC5.
Tällainen “lohkon salaus” -lähestymistapa asettaa kuitenkin rajoituksia laitteiston suorituskyvylle, datanprosessoinnille ja puskuroinnille, koska salaus pitää toteuttaa ennen kuin seuraava data-annos saapuu. Teolliset salausjärjestelmät yli 200 Mbps datanopeutta, mutta tämä – yleensä ASIC-pohjainen – laitteisto on hyvin kallis verrattuna yksinkertaiseen mikro-ohjaimeen. Vaikka onkin mahdollista toteuttaa salaus yksinkertaisella 8-bittisellä mikro-ohjaimella ja ulkoisella muistilla 8051-tyyliin, salaus vie kertaluokkia enemmän aikaa kuin sama prosessi ASIC-piirillä.
Tämä artikkeli selvittää, kuinka ohjelmoitavaa logiikkaa sisältävä SoC-järjestelmäpiiri voi hyödyntää mikro-ohjainydintä ja sen lisäresursseja kuten universaaleja digitaalisia lohkoja (UBD, Universal Digital Blocks) ja DMA-lohkoja (Direct Memory Access) salauksen tehokkaaseen toteutukseen, joka parantaa koko järjestelmän suorituskykyä.
AES on yksi yleisimpiä symmetriseen avaimeen perustuvia lohkonsalaustekniikoita. Käytämme esimerkkinä AES-128:aa, joka operoi 16-tavuisilla (128-bittisillä) datapaketeilla ja 128-bittisellä salausavaimella. Sen avulla näemme hyvin salaussovellusten vaatimukset ja mahdolliset toteutusvaihtoedot. AES-128:ssa input- eli syötetavut on järjestetty lohkon muotoon ennen kuin prosessointi alkaa, kuten kuvassa 1 on esitetty. Tässä kuvassa in0 on ensimmäinen tavu ja in15 viimeinen syötelohkon kuudestatoista tavusta.
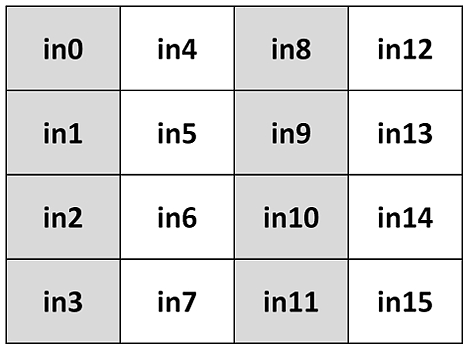
Kuva 1. Syötetavut.
Tavujen korvaaminen
Ensimminen operaatio on tavujen korvaaminen. Tässä vaiheessa jokainen syötteen tavu korvataan aiemmin määritellystä korvaustaulukosta valitulla tavulla. Valittu arvo löytyy taulukon kohdasta, johon syötetavu viittaa, kuten kuvassa 2 on esitetty. Minkä tahansa tavun S korvaaminen rivillä ja palstalla voidaan ilmaista näin:
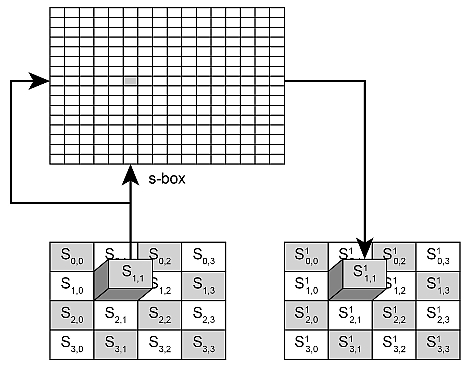
Kuva 2. Tavujen korvaaminen.
Korvaustaulukko yleensä kovakoodataan piirille (Flash-, SRAM- tai muuhun muistiin). Kun prosessorille osoitetaan tavun vaihtamisen tehtävä, se noutaa syötetavun ohjelmamuistista ja siirtää sen eteenpäin osoitteena SRAM-muistille. Sen jälkeen SRAM palauttaa ko. paikassa olevan tavun. Tämä prosessi vie paljon aikaa ennenkuin korvaukset koko lohkossa on tehty.
Jotta CPU:n voisi vapauttaa näistä kaikista operaatioista, voidaan korvaaminen tehdä samanaikaisesti DMA-osoitinten avulla, mikä vapauttaa CPU:n muihin tehtäviin. DMA:lle täytyy osoittaa vain muistinlähde ja -kohde, ja se huolehtii datansiirrosta. Lisäksi, sen sijaan että nämä arvot siirrettäisiin joihinkin tiettyihin muistipaikkoihin, DMA voi siirtää datan suoraan UDB-lohkoon jatkoprosessointia varten ilman CPU:n väliintuloa.
Rivin vaihto
Seuraava vaihea AES-salauksessa on rivin vaihto (Row Shifting). Tässä vaiheessa jokaisen vaihdetun tavun syötelohko siirretään vasemmalle yhdellä tavulla. Tämä siirretty tavu ottaa oikeimmalla olevan tavun paikan. Ensimmäisellä rivillä rivinvaihtoa ei tapahdu. Toisella rivillä rivinvaihto tehdään kerran, kolmannella rivillä kaksi keraa ja neljännellä rivillä kolmasti. Tämä prosessi on esitetty kuvassa 3.
CPU voi suorittaa vain 8-bittisiä operaatioita, eikä se näin ollen voi nähdä koko lohkoa. Tarkalleen ottaen rivinvaihto siirtää tavun paikkaa. Esimerkiksi rivinvaihdon jälkeen tavu S1,0 ottaa tavun S1,3 paikan. Siten DMA voi osoittautua paljon tehokkaammaksi valitessaan tavua yhdestä osoitteesta ja siirtäessään sen toiseen.
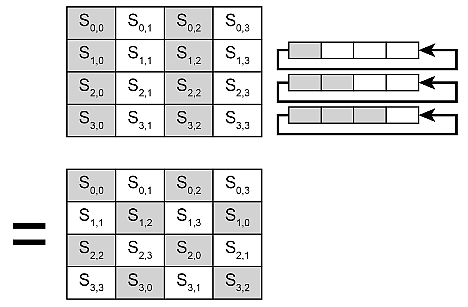
Kuva 3. Rivin vaihto.
Sarakkeiden sekoitus
Rivin vaihdon jälkeen seuraava askel on sarakkeiden sekoitus. AES-sarakkeiden sekoituksessa datablokki muunnetaan niin, että yksi täysi sarake (4 tavua) prosessoidaan generoimaan yksi tavu. Tämä muunnos tapahtuu tarkalleen ottaen kertomalla GF(28) polynomilla p(x) = x8 + x4 + x3 + x + 1. Sarakkeen sekoituksen matriisiesitys on esitetty kuvassa 4.
Matemaattisesti tavuA tuotetaan a,b,c ja d:stä yhtälöllä

Kertolaskun toteuttaminen laitteistossa on aina ollut haastava tehtävä, minkä takia tätä yhtälöä ei yleensä toteuteta tässä muodossa. Kirjan Cryptography and Network Security, mukaan arvon kertominen x:llä (eli tässä 02:lla) voidaan toteuttaa yhden bitin siirrolla vasemalle ja sitä seuraavalla bittisuuntaan kulkevalla XOR-operaatiolla, jossa kaikkein vasemmalla olevan bitin alkuperäinen arv (ennen siirtoa) on 1. Tämän säännön mukaan ylläoleva yhtälö yksinkertaistuu muotoon:

Tämä yksinkertainen muunnos voi merkittävästi vähentää niitä laiteresursseja, joita sarakkeiden sekoittamiseen tarvitaan.

Kuva 4. Sarakkeiden sekoittaminen
Järjestelmäpiiri, jonka arkkitehtuuri on ohjelmoitava, voi toteuttaa tämän prosessin tehokkaasti laitetasolla. Esimerkiksi Cypressin PSoC-arkkitehtuurissa universaalit digitaaliet lohkot eli UDB-lohkot ovat erinomainen kandidaatti sarakkeiden sekoittamisen toteutukseen. Kuva 5 näyttää UDB-arkkitehtuurin Cypressin teknisestä ohjekirjasta (PSoC Technical Reference Manual).
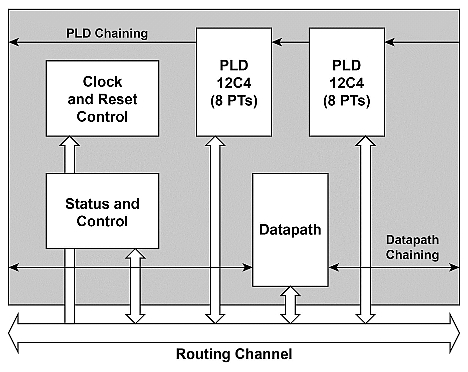
Kuva 5. PSoC-piirin universaalit digitaalilohkot (UDBs).
Yllänäkyvät tavun levyiset operaatiot voidaan kaikki ajaa datapolussa yhden kellojakson aikana. Ennen kuin siirrytään todelliseen toteutukseen UDB-lohkoilla, on tärkeää ymmärtää datapolun sisäinen rakenne.
UDB-lohkon datapolku koostuu kahdesta 4-tavuisesta FIFO-muistista, kahdesta datarekisteristä, kahdesta kiihdytinrekisteristä ja 8-bittisestä ALU-laskentayksiköstä (aritmetiikka-logiikka-yksikkö). Nämä laiteresurssit saadaan toimimaan tilakoneen (state machine) avulla. Nämä 8 tilaa voidaan konfiguroida Data Path Configuration -työkalulla:
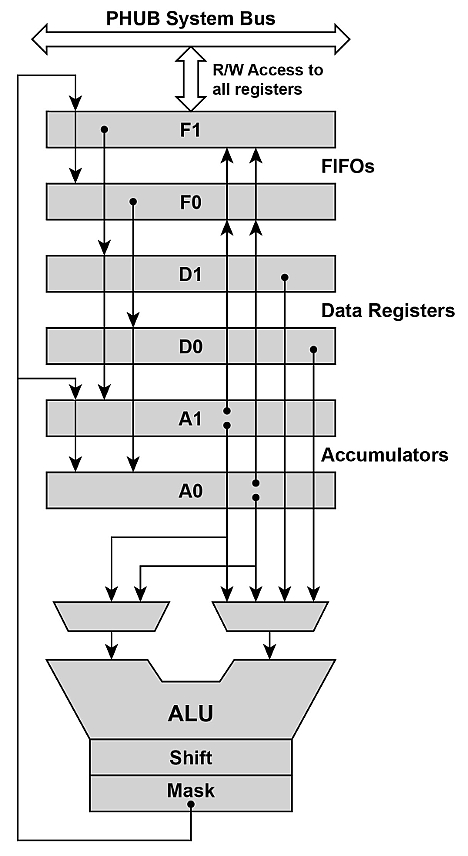
Kuva 6. Datapolku PSoC:n UDB-lohkoissa.
Kuva 7 näyttää tilakoneen sarakkeiden sekoitusoperaatiolle eli yhtälö iii:lle (UDB:tä hyödyntäen).
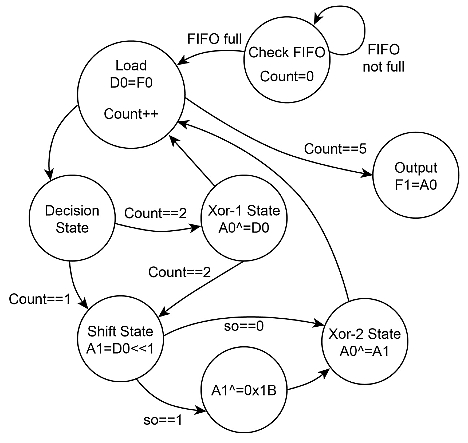
Kuva 7. Tilakone UDB-lohkojen avulla toteutettuun sarakkeiden sekoitukseen.
Kuvan yhtälöstä voidaan nähdä, että a, b, c ja d vaaditaan generoimaan tavu A. Tässä voidaan käyttää 4-tavuisia FIFOja. Datapolku pysyy Check FIFO -tilassa kunnes kaikki 4 tavua on vastaanotettu ja syöte-FIFO on täynnä. Sen jälkeen datapolku siirtyy Load-tilaan, jossa se hakee tavun FIFOlta ja siirtää sen kertolaskimeen (accumulator) jatkoprosessointia varten. Lisälaitteistolla (PLD-piirillä) voidaan toteuttaa laskin, joka pitää kirjaa jokaisesta tavusta, koska jokainen tavunvaihtoa käsitellään eri tavoin. Lisäksi, koska tavu a pitää kertoa 2:lla (check_msb(a<<1)), tilakone siirtää sen Shift-tilaan, missä se siirretään vasemmalle yhdellä bitillä. Siirretty bitti (so kuvassa 7) määrittää, pitääkö sille suorittaa XOR-operaatio 0x1B:llä.
Samoin laskin lisää ja tilakone operoi jokaista tavua yhtälön iii mukaan. Kun laskin nousee 5:een eli kaikki tavut on ladattu ja syöte-FIFO on tyhjä, tulos voidaan ladata FIFO-lähtöön. Prosessori voi nyt noutaa sekoitetun tavun FIFOsta, kun keskeytys (FIFO-lähtö on tyhjä) on generoitu. Näin sarakkeiden sekoittamisen siirto UDB-lohkoille voi merkittävästi vähentää CPU:n prosessointia.
Koko sarake (4-tavuinen) voidaan generoida käyttämällä kolmea samanlaista lisädatapolkua. Ainoa ero syntyy laskimen tarkistuksista.
Avaimen laajennus ja uusien avaimien lisääminen
Viimeinen askel AES-salauksessa on avainten laajennus (Key Expansion) ja uusien avaimien lisääminen (Roudn Key Addition). AES-128:n avaimen laajennuksessa 128-bittisestä avaimesta generoidaan yksitoista 128-bittistä RK-lohkoa (Round Key blocks). Jokaiselle lohkolle suoritetaan XOR-operaatio tavu tavulta datalohkon kera. Avaimen laajennusprosessi esitetään kuvassa 8. Jokainen RK-lohko generoidaan edellisen RK:n pohjalta. Ensimmäinen RK generoidaan todellisen 128-bittisen avaimen perusteella. Jos RK(n-1) on edellinen RK ja RK(n) nykyinen RK, silloin RK(n):n sarake generoidaan ensimmäisellä tavulla, joka korvaa viimeisen sarakkeen RK4(n-1):ssä ja siirtää sen pystysuoraan taulukossa ylöspäin. Tämän jälkeen tälle sarakkeelle suoritetaan XOR-operaatio tavu tavulta ensimmäisen sarakkeen RK(n-1):n kanssa, jotta saadaan RK(n):n ensimmäinen sarake. Vastaavalla periaatteella generoidaan muut sarakkeet.
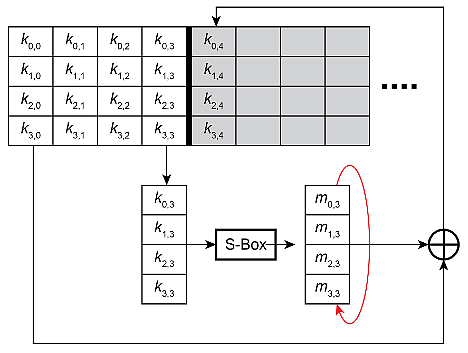
Kuva 8. Avaimen laajennus.
Avaimen laajennus ja uusien avainten lisääminen vaativat muistia aiempien ja uusien 128-bittisten avaimien tallentamiseen, sekä välitulosten varastointiin. Se edellyttää myös tavutason XOR-operaatioita. DMA:ta voidaan käyttää noutamaan tavut S-laatikosta (ks. Kuva 8), ja syöttämään yhden tavun kerrallaan UDB-lohkoihin. Yksinkertaisen datapolku-tilakoneen avulla UDB voi siirtää tätä saraketta pystysuoraan. Tulos (output) voidaan lukea joko CPU:lla tai DMA:lla. Tämä sarake voidaan syöttää uudelleen datapolun FIFOon yhdessä ensimmäisen sarakkeen kanssa tavu-tavulta tapahtuvaa XOR-operaatiota varten.
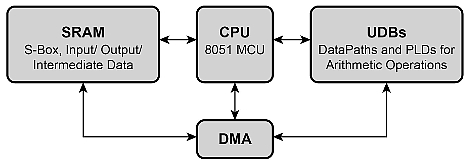
Kuva 9. Digitaalisten lohkojen (UDB) ja DMA:N integrointi PSoC-piirillä salauksessa.
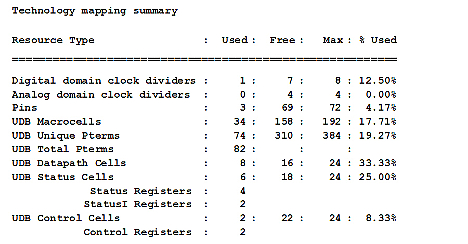
Kuva 10. Resurssien käyttö sarakkeiden sekoitusoperaatiossa.
PSoC-piirien lisälaitteistoresurssien avulla suunnittelu käyttää noin 34 prosenttia vähemmän laskentajaksoja salaukseen kuin perinteinen CPU-pohjainen salaus. Kesketysten avulla CPU-rasitus pienenee entisestään, ja prosessien osittainen tai kokonaan siirto ulkoisille resursseille johtaa nopeampaan ja tehokkaampaan AES-toteutukseen.
 Tekoäly siirtyy pilvestä koneisiin, kameroihin, antureihin ja robotteihin. Reunalla yksi laitteistoratkaisu ei kuitenkaan sovi kaikkeen, vaan suorituskyky on sovitettava mallin, datan ja käyttökohteen mukaan.
Tekoäly siirtyy pilvestä koneisiin, kameroihin, antureihin ja robotteihin. Reunalla yksi laitteistoratkaisu ei kuitenkaan sovi kaikkeen, vaan suorituskyky on sovitettava mallin, datan ja käyttökohteen mukaan.