








Toisin kuin GPT-4, jonka malliarkkitehtuurit ja datat ovat suurelta osin suljettuja, NVLM 1.0 julkaisee malliensa painot ja avaa koodinsa tutkimusyhteisön käyttöön. Tämä tarjoaa merkittävän edun tutkimuksen ja kehityksen kannalta.
NVLM 1.0:ssa on kolme arkkitehtuurivaihtoehtoa: decoder-only (NVLM-D), cross-attention (NVLM-X) ja hybridi-arkkitehtuuri (NVLM-H). Tämä eroaa GPT-4:n yhden neuroverkon mallista, joka käsittelee teksti- ja kuvasyötteitä ilman erillisiä moduuleja. NVLM tarjoaa erillisiä arkkitehtuurivaihtoehtoja, joista jokaisella on vahvuutensa erilaisissa laskentatehtävissä.
NVLM 1.0 on suunniteltu erityisesti kuvien tunnistukseen ja muihin visuaalis-kielellisiin haasteisiin. Se käyttää dynaamisia korkearesoluutioisia kuvia, mikä parantaa suorituskykyä tehtävissä, kuten tekstintunnistuksessa ja matemaattisessa päättelyssä. GPT-4 on erittäin monipuolinen, mutta se ei ole yhtä optimoitu skannattuihin tai korkearesoluutioisiin kuviin liittyvissä tehtävissä.
GPT-4 on tunnettu kyvystään toimia hyvin sekä teksti- että multimodaalisissa tehtävissä ilman suorituskyvyn heikkenemistä. NVLM 1.0, erityisesti NVLM-D-versio, parantaa multimodaalikoulutuksen aikana jopa mallin tekstipohjaista suorituskykyä matemaattisissa ja koodauksen prosessoinnissa.
GPT-4:n vahvuus on sen kyky yhdistää teksti- ja kuvadatan käsittely sujuvasti. Vaikka NVLM tarjoaa myös kattavan multimodaalikäsittelyn, se eriyttää kuvat ja tekstin eri moduuleilla, mikä voi tarjota enemmän joustavuutta, mutta saattaa olla vähemmän sujuva käytössä kuin GPT-4:n yhtenäinen malliarkkitehtuuri.






 Autoteollisuus on siirtymässä yhä monimutkaisempiin ohjelmistopohjaisiin järjestelmiin, joissa virheetön ohjelmisto on elintärkeää turvallisuuden ja suorituskyvyn varmistamiseksi. Ohjelmiston laatu ja luotettavuus eivät ole enää vain valinnaisia ominaisuuksia, vaan kriittisiä vaatimuksia erityisesti autonomisessa ajamisessa, kehittyneissä kuljettajaa avustavissa järjestelmissä (ADAS) ja yhdistetyissä ajoneuvojärjestelmissä.
Autoteollisuus on siirtymässä yhä monimutkaisempiin ohjelmistopohjaisiin järjestelmiin, joissa virheetön ohjelmisto on elintärkeää turvallisuuden ja suorituskyvyn varmistamiseksi. Ohjelmiston laatu ja luotettavuus eivät ole enää vain valinnaisia ominaisuuksia, vaan kriittisiä vaatimuksia erityisesti autonomisessa ajamisessa, kehittyneissä kuljettajaa avustavissa järjestelmissä (ADAS) ja yhdistetyissä ajoneuvojärjestelmissä.
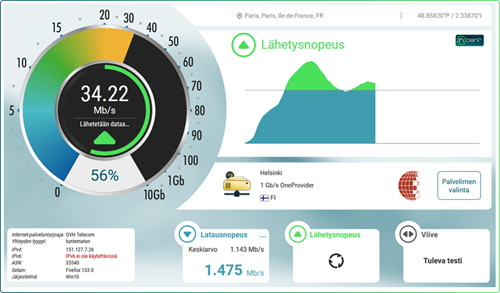
 Kestävä digitaalinen infrastruktuuri on kriittinen, jotta tietoliikenneverkot voidaan tehokkaasti valjastaa tekoälyinnovaatioiden ja pilvipohjaisten palveluiden tarpeisiin. Tekoälyyn liittyvien datarikkaiden sovellusten lisääntyvä kysyntä edellyttää tietoliikenneverkkoa, joka kykenee käsittelemään suuria tietomääriä alhaisella viiveellä, kirjoittaa Orange Businessin kumppaniratkaisuista vastaava Carl Hansson.
Kestävä digitaalinen infrastruktuuri on kriittinen, jotta tietoliikenneverkot voidaan tehokkaasti valjastaa tekoälyinnovaatioiden ja pilvipohjaisten palveluiden tarpeisiin. Tekoälyyn liittyvien datarikkaiden sovellusten lisääntyvä kysyntä edellyttää tietoliikenneverkkoa, joka kykenee käsittelemään suuria tietomääriä alhaisella viiveellä, kirjoittaa Orange Businessin kumppaniratkaisuista vastaava Carl Hansson. Euroopan unioni ottaa merkittävän askeleen avaruusteknologian kehittämisessä allekirjoittamalla sopimuksen uuden IRIS²-satelliittijärjestelmän toteuttamisesta. Tämä 290 satelliitin verkko on suunniteltu vahvistamaan Euroopan itsenäisyyttä ja turvallista yhteydenpitoa.
Euroopan unioni ottaa merkittävän askeleen avaruusteknologian kehittämisessä allekirjoittamalla sopimuksen uuden IRIS²-satelliittijärjestelmän toteuttamisesta. Tämä 290 satelliitin verkko on suunniteltu vahvistamaan Euroopan itsenäisyyttä ja turvallista yhteydenpitoa.


 Jotta voidaan vastata uuden teknologian vaatimuksiin ja pitää järjestelmät toimimassa ”kellon tavoin”, on aika harkita ajoitusratkaisuja uudelleen. Tässä kaksiosaisessa "Precision Timing" -artikkelissa opit, miksi mikroelektromekaanisiin järjestelmiin eli MEMS-komponentteihin perustuvat piiajoituslaitteet päihittävät kvartsin elektroniikkasuunnittelun uudella aikakaudella.
Jotta voidaan vastata uuden teknologian vaatimuksiin ja pitää järjestelmät toimimassa ”kellon tavoin”, on aika harkita ajoitusratkaisuja uudelleen. Tässä kaksiosaisessa "Precision Timing" -artikkelissa opit, miksi mikroelektromekaanisiin järjestelmiin eli MEMS-komponentteihin perustuvat piiajoituslaitteet päihittävät kvartsin elektroniikkasuunnittelun uudella aikakaudella. 

 Matalatehoisten langattomien ratkaisujen asiantuntija Nordic Semiconductor ja eSIM-ratkaisuja kehittävä Kigen ovat julkistaneet yhteistyön, joka sujuvoittaa massiivisten IoT-verkkojen käyttöönottoa. Yhdessä he esittelevät CES 2025 -messuilla ratkaisun, joka yhdistää Nordic Semiconductorin nRF9151-moduulin ja Kigenin SGP.32 IoT eSIM-teknologian sekä laitteiden hallinta-alustan.
Matalatehoisten langattomien ratkaisujen asiantuntija Nordic Semiconductor ja eSIM-ratkaisuja kehittävä Kigen ovat julkistaneet yhteistyön, joka sujuvoittaa massiivisten IoT-verkkojen käyttöönottoa. Yhdessä he esittelevät CES 2025 -messuilla ratkaisun, joka yhdistää Nordic Semiconductorin nRF9151-moduulin ja Kigenin SGP.32 IoT eSIM-teknologian sekä laitteiden hallinta-alustan.




