Yhä useampi sovellus hyödyntää jonkinlaista tekoälyä. Usein ajatellaan, että syväneuroverkon opettaminen vaatii palvelinfarmeittain laskentatehoa, mutta tilanne on hiljalleen muuttumassa. Tekoäly on tulossa myös sulautettuihin.
Yhä useampi sovellus hyödyntää jonkinlaista tekoälyä. Usein ajatellaan, että syväneuroverkon opettaminen vaatii palvelinfarmeittain laskentatehoa, mutta tilanne on hiljalleen muuttumassa. Tekoäly on tulossa myös sulautettuihin.
|
Artikkelin kirjoittaja Cliff Ortmeyer vastaa Premier Farnellin ratkaisujen kehittämisestä. Ortmeyer tuli Farnellin palvelukseen vuonna 2011. Sitä ennen hän työskenteli STMicroelectronicsilla liiketoiminnan kehityksessä yli 13 vuotta. Ortmeyerillä on elektroniikkainsinöörin tutkinto Iowa State Universitystä. |
Tekoäly eli AI (Artificial intelligence) nähdään nyt elintärkeäksi osaksi esineiden internetin ja esimerkiksi robottien ja autonomisten ajoneuvojen kehittämisessä.
Monien kotien olohuoneissa pöydällä makaava älykaiutin on hyvä esimerkiksi edistyneen tekoälyn toiminnasta arkipäivässämme. Se kykenee tunnistamaan luonnollista kieltä ja syntesoimaan korkealaatuista puhetta. Tässä onnistuakseen kaiuttimen täytyy siirtää dataa useille tehokkaille tietokoneille etäisissä palvelinfarmeissa. Sulautettu laitteisto nähdään liian rajoittavana kyetäkseen ajamaan niitä syväneuroverkkojen (DNN, deep neural network) algoritmeja, joihin nämä toiminnot perustuvat.

Tekoälyn sovellukset
Tekoälyn ei tarvitse rajoittua käytettäväksi vain huipputehoisissa palvelimissa konesaleissa. Tekoälytekniikoita ehdotetaan nyt tavaksi hallita äärimmäisen monimutkaista 5G NR- eli New Radio -protokollaa. Puhelimien täytyy analysoida niin suuri määrä kanavaparametreja optimoidun datanopeuden saavuttamiseksi, että se on ylittänyt suunnittelijoiden kyvyn kehittää tehokkaita algoritmeja. Kenttätestien aikana kerätyn datan perusteella koulutetut algoritmit ovat tehokas keino tasapainottaa eri asetusten välisiä ominaisuuksia.
Mitä tulee etäisissä kohteissa toimivien teollisuuslaitteiden kunnon ylläpitämiseen, sulautetulla raudalla ajettavat koneoppimisalgoritmit ovat tulossa tehokkaaksi vaihtoehdoksi. Perinteiset algoritmit kuten Kalman-suotimet käsittelevät jo erilaisten datasyötteiden, kuten paineen, lämpötilan ja tärinän lineaarisia suhteita. Silti ongelmista varoittaminen etukäteen tapahtuu usein tunnistamalla muutoksia suhteissa, jotka eivät ole pääosin lineaarisia.
Tekoälytoteutukset
Järjestelmiä voidaan opettaa terveistä ja pettävistä laitteista peräisin olevalla datalla tunnistamaan potentiaalisia ongelmia, kun niihin syötetään reaaliaikaista toimintadataa. Tässä kohtaa neuraaliverkko, vaikka onkin suosittu valinta nykyään, ei ole ainoa mahdollinen tekoälyratkaisu. On olemassa monia algoritmeja, joita voidaan hyödyntää ja vaihtoehtoinen ratkaisu voi olla kaikkein sopivin käsillä olevan ongelman ratkaisemiseksi.
Yksi mahdollinen ratkaisu voi löytyä sääntöperustaisesta tekoälystä. Tämä hyödyntää erikoisalueen asiantuntijoiden osaamista suoraan koneoppimisen sijaan enkoodaamalla asiantuntijoiden tietoa sääntökannassa. Päättely- eli inferenssimoottori analysoi dataa sääntöjä vastaan ja yrittää löytää parhaan vastaavuuden kohtaamilleen olosuhteille. Sääntöperustainen järjestelmä ei vaadi valtavasti laskentatehoa, mutta kehittäjät voivat kohdata ongelmia, mikäli olosuhteita on vaikea kuvata yksinkertaisin lausekkein tai syötedatan ja toiminnan suhteita ei ymmärretä hyvin. Viimeksi mainittu pätee puheeseen ja kuvantunnistukseen, mikä koneoppiminen on osoittanut loistavansa.
Koneoppiminen on läheisessä suhteessa optimointiprosesseihin. Annetuilla tietokannan elementtien syötteillä koneoppimisalgoritmi yrittää löytää sopivimman tavan niiden luokitteluun tai järjestämiseen. Lineaarisen regressioanalyysin kaltaisiin tekniikoihin perustuvaa käyrän sovitusalgoritmia voidaan pitää koneoppimisalgoritmin yksinkertaisimpana muotona: se käyttää datapisteitä formuloidakseen parhaiten sopivan polynomin, jota voidaan käyttää määrittelemään todennäköisin tuotos annetulle syötedatalle. Käyrän sovitus sopii vain järjestelmiin, joissa on hyvin vähän ulottuvuuksia. Todelliset koneoppimissovellukset voivat käsitellä monimutkaista moniulotteista dataa.
Ryhmittäminen menee pidemmälle luokittelemalla datan ryhmiin. Tyypillinen algoritmi perustuu painopisteisiin, mutta myös monia muita klusterianalyysejä käytetään koneoppimisessa. Painopistepohjainen järjestelmä käyttää geometristä etäisyyttä datapisteiden välillä sen määrittelemiseen, mihin ryhmään ne kuuluvat. Klusterianalyysi on usein iteratiivinen prosessi, jossa erilaisia kriteereitä käytetään määrittelemään, missä rajata ryhmine/klusterien välillä muodostuvat ja kuinka läheisiä datapisteiden täytyy olla suhteessa toisiinsa yksittäisessä klusterissa. Tekniikka on kuitenkin tehokas niiden kuvioiden löytämisessä datasta, joita domain-asiantuntijat eivät löytäisi. Toinen tapa erotella data luokkiin on SVM-moottori (support vector machine), joka jakaa moniulotteisen datan luokkiin hypertasoilla, jotka luodaan optimointitekniikoilla.
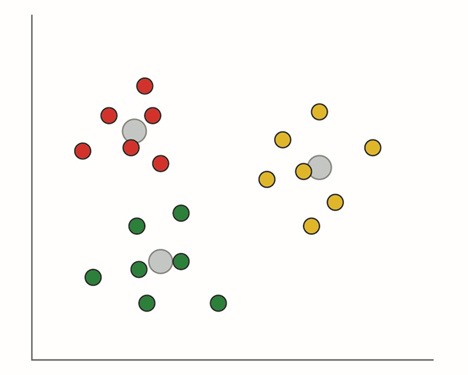
Kuva 1. Klusterointi käyttää mekanismeja kuten etäisyyttä lähimmästä painopisteestä datan luokitteluun.
Päättelypuu tuottaa tapoja käyttää klusteroitua/ryhmiteltyä dataa sääntökannassa. Päättelypuun ansiosta tekoälyalgoritmi voi työstää datasyötteitä vastauksen kehittämiseksi. Jokainen koodihaara puussa voidaan määritellä syötedatan klusterianalyysillä. Järjestelmä voi esimerkiksi käyttäytyä eri tavoin tietyn lämpötilan yläpuolella niin, että painelukema on hyväksyttävä muissa olosuhteissa. Tämä voi vihjata ongelmaan. Päättelypuu voi käyttää näiden olosuhteiden yhdistelmiä löytääkseen sopivimman sääntökokoelman ko. tilanteelle.
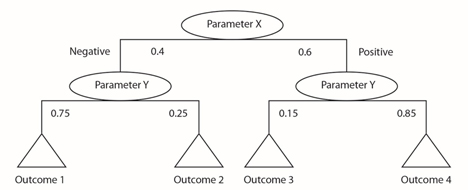
Kuva 2. Päättelypuu antavat keinon strukturoida dataa luokittelusääntöjen ja erilaisten seurausten todennäköisyyksien perusteella.
Vaikka syväneuroverkot yleisesti edellyttävät suorituskykyistä laitteistoa reaaliaikaiseen prosessointiin, on olemassa yksinkertaisempia rakenteita kuten vastakkaisia (adversarial) neuroverkkoja, joita on menestyksellä sovellettu 32- ja 64-bittisiin prosessoreihin perustuvissa mobiiliroboteissa, jollainen löytyy esimerkiksi Raspberry Pi -alustoista. Syväneuroverkkojen avainetu on sen suuressa kerrosten määrässä. Kerrostettu rakenne mahdollistaa sen, että neutronit voivat enkoodata yhteyksiä moniulotteisten dataelementtien välillä, jotka voivat olla tilallisesti ja ajallisesti kaukana toisistaan, mutta joiden välillä on koulutusprosessin aikana paljastuneita tärkeitä suhteita.
Se lisäksi, että edellyttää tehokasta laitteistoa, syväneuroverkkojen huono puoli on se valtava datamäärä, joka sen opettamiseen tarvitaan. Tässä muut algoritmit kuten Gaussian-prosesseihin perustuvat tulevat tekoälytutkijoiden kiinnostuksen kohteeksi. Ne käyttävät datan todennäköisyysanalyysiä rakentaakseen mallin, joka toimii neuroverkon tavoin mutta käyttää paljon vähemmän koulutusdataa. Lyhyellä tähtäimellä syväneuroverkkojen menestys tekee niistä kuitenkin pääehdokkaan monimutkaisten moniulotteisten syötteiden käsittelyyn, kuten kuvien, videon tai audio- ja prosessidatavirtojen käsittelyyn.
Yksi vaihtoehto monimutkaisten vaatimusten sovelluksissa on käyttää yksinkertaista tekoälyalgoritmia sulautetussa laitteessa etsimään syötedatasta poikkeavuuksia ja sen jälkeen pyytää palvelua pilvestä katsotaan dataa yksityiskohtaisemmin tarkemman vastauksen löytämiseksi. Tällainen jako helpottaisi reaaliaikasuorituskyvyn säilyttämisessä, rajoittaisi pitkien matkojen yli siirrettävän datan määrää ja varmistaisi toiminnan jatkumisen jopa satunnaisten verkkokatkosten aikana. Mikäli yhteys menetetään, sulautettu järjestelmä voi tallentaa epäilyttävän datan välimuistiin, kunnes tulee jälleen mahdollisuus tarkistaa se pilvipalvelussa.
Tekoälytoimittajat
Amazon Web Services (AWS) ja IBM kuuluvat niihin yrityksiin, jotka nyt tarjoavat pilvipohjaisia tekoälypalveluja asiakkailleen. AWS antaa pääsyn laajaan valikoimaan koneoppimiseen sopivia laitealustoja, kuten yleiskäyttöiset palvelinkortit, GPU-kiihdyttimet ja FPGA-piirit. Pilvessä ajettavat syväneuroverkot voidaan rakentaa avoimen koodin kehyksillä kuten Caffe ja TensorFlow, joita tekoälykehittäjät nyt laajasti käyttävät.
IBM on rakentanut suorat liitännät Watson-tekoälyalustaansa esimerkiksi Raspberry Pi -kortille, joten sillä on helppo prototypoida koneoppimissovelluksia ennen kuin lyö lopullisen arkkitehtuurin lukkoon. Arm tarjoaa vastaavanlaisen liitännän Watsoniin oman mbed IoT -alustansa kautta.
Vaikka tekoäly saattaa näyttää laskennan uudelta rintamalta, suorituskykyisten mutta edullisten Raspberry Pin kaltaisten korttien saatavuus sekä pääsy pilvipohjaisiin koneoppimispalveluihin tarkoittaa, että sulautettujen kehittäjillä on suoraviivainen pääsy koneoppimisalgoritmien kirjoon, joka parin viimeisen vuosikymmenen aikana on kehitetty. Kun yhä edistyneempiä tekniikoita kehitetään, kortti- ja pilvilaskennan yhdistelmä varmistaa sen, että sulautettujen sovellusten kehittäjät pysyvät kehityksen vauhdissa mukana ja voivat kehittää älykkäimpiä mahdollisia ratkaisuja.
 Tekoäly siirtyy pilvestä koneisiin, kameroihin, antureihin ja robotteihin. Reunalla yksi laitteistoratkaisu ei kuitenkaan sovi kaikkeen, vaan suorituskyky on sovitettava mallin, datan ja käyttökohteen mukaan.
Tekoäly siirtyy pilvestä koneisiin, kameroihin, antureihin ja robotteihin. Reunalla yksi laitteistoratkaisu ei kuitenkaan sovi kaikkeen, vaan suorituskyky on sovitettava mallin, datan ja käyttökohteen mukaan.